David holland
Regular
Watch the FinancialsLet me guess… the shorter are back and want to fish every penny they can get from the last bounce? It’s ridiculous! Or classic brainchip manipulation!
Watch the FinancialsLet me guess… the shorter are back and want to fish every penny they can get from the last bounce? It’s ridiculous! Or classic brainchip manipulation!
Not on an autobahn.Dio.. ?? Would 'you' be breaking the speed limit??")
I don’t understand Netherlandish i already told you that.Watch the Financials

After reading this post adding in the ARM partnership, the CRO Edge Impulse statement of AKIDA in every semiconductor and Sean Hehir CEO stating Brainchip intends to be one of the two to three major players in this space I think it is safe to conclude one percent of the Edge Ai market is the least Brainchip will achieve.We get a tag amongst some big names here, and Rob likes it.
Not a small company.......10k employees, she is very excited about neuromorphic computing.

#neuromorphiccomputing #ai #futureoftech #nvidia #intel #ibm #microsoft #google #brainchip #nxp #cerebrassystems #inbrainneuroelectronics #nervanasystems #syntiantcorp #automotive #healthcare… | Ronit Gabizon VP of Business Development
The Neuromorphic Revolution: Redefining AI and Problem-Solving! Hey LinkedIn community! Brace yourselves for the neuromorphic revolution, a cutting-edge field reshaping how we approach technology and artificial intelligence (AI). What's Neuromorphic Computing? Think computers mirroring the...www.linkedin.com

IEC - Israel Electric Corporation חברת החשמל לישראל בע"מ | LinkedIn
IEC - Israel Electric Corporation חברת החשמל לישראל בע"מ | 22,348 followers on LinkedIn. The Israel Electric Corporation (IEC) is a public, government company, 99.85% of its shares are government-owned and traded on the Tel-Aviv and Singapore stock exchange. Company activities include...
View attachment 56241
View attachment 56238 View attachment 56239 View attachment 56240
Is that all?
You have to double it.I don’t understand Netherlandish i already told you that.
Home | The Financials
www.thefinancials.nl
Hi JBhttps://arxiv.org/html/2401.06911v1
"Furthermore, due to the runtime limitation of 20 minutes for jobs on Intel’s cloud, on-chip training was not possible, restricting the exploration of this important capability of Loihi".
Akida can solve that.

 www.arm.com
www.arm.com
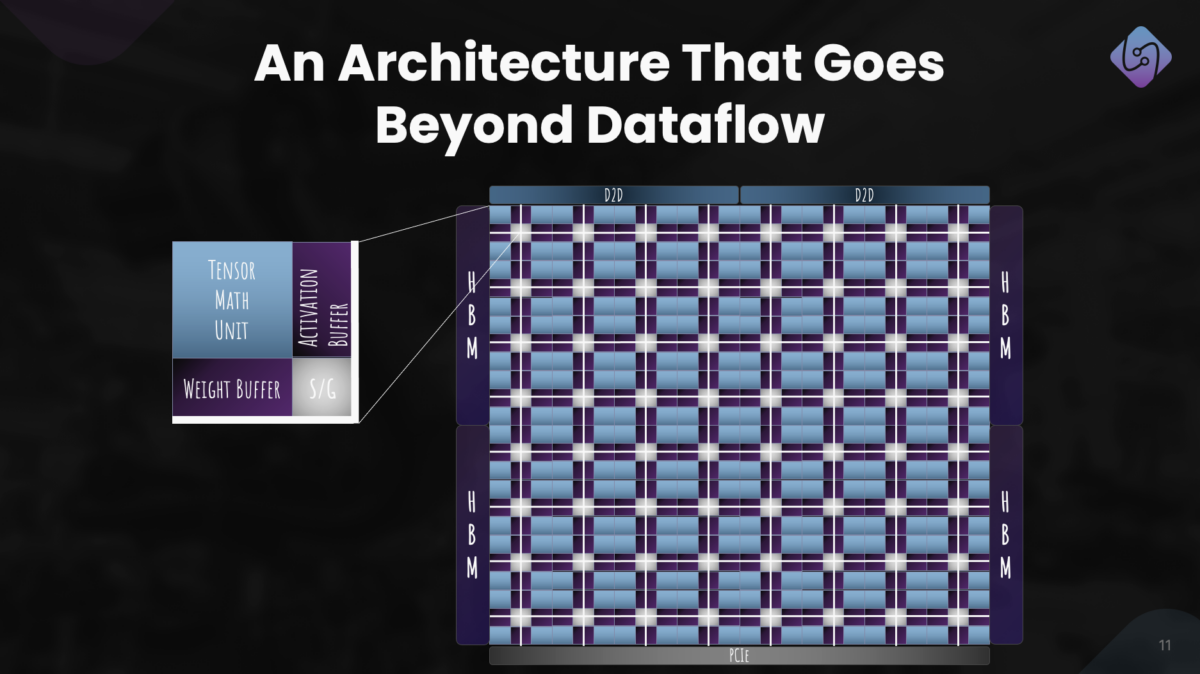
Someone could produce a graph showing Loihi and Akida performance except we wouldn't be on the same page.Hi JB
This is an important find. I have taken the following extract to cover the facts you have revealed:
Regarding the digital beamforming performance for fast-moving users, we compared the conventional LASSO solution provided by CVX [13] running on Matlab with the solution of S-LCA on Intel’s Lava simulator. Firstly, it is worth highlighting that the proposed beamforming formulation yielded sparse beamforming vectors, with both solutions being able to turn off up to 60% of the RF chains without compromising the resulting beampatterns. Regarding performance comparisons between the two solutions, both generated satisfactory beampatterns with the main lobe pointing toward the aircraft. For a numerical comparison, the beamformer’s average output power was considered as key performance indicator to assess the beamforming capabilities to mitigate the effects of noise and interference while focusing on the desired signal direction. In this context, the S-LCA solution was able to reach lower levels of beamformer’s average output power, around 19% below the value reached by the CVX solution, but with a much higher spreading of values, around 4 times higher than the CVX solution, when comparing the lower and upper quartiles of beamformer’s average output power.
- •
Superiority of SNN and Loihi 2: The results highlight that, in all cases, Intel’s Loihi 2 performs better than the CNN implemented in Xilinx’s VCK5000. However, it is worth noting that, as the batch size increases, the advantage of Loihi became less pronounced as the performance points move closer to the EDP line, although it still outperforms the Xilinx’s VCK5000 implementation.- •
Interference detection as a promising use case: Among the considered scenarios, it seems that the interference detection and classification benefited the most from the implementation on Intel’s Loihi chipset. Even though the time ratio remained generally higher than one, the energy savings achieved with Loihi were significant. In some cases, the energy ratio reached values as high as 105- •
SNN encoding: Fig. 3 compares the impact of FFT Rate and FFT TEM encoding for the ID scenario. Interestingly, the type of coding used did not have a significant impact on this comparison.- •
RRM’s Performance: While RRM did not achieve energy savings as pronounced as in the ID scenario, it consistently achieved an energy ratio exceeding 102
V-ARemarks about the results obtained with Intel’s Loihi 2
The results presented in this article were conducted with Loihi 2 but using the remote access from Intel’s research cloud. Although Intel offers the possibility of shipping physical chips to INRC partners premises, at the moment of developing these results the primary access to Loihi 2 was through the Intel’s neuromorphic research cloud. Obviously, the remote access introduced some additional limitations as it was not possible to control for concurrent usage by other users, which could lead to delays and increased power consumption. Additionally, the specific interface used by Intel on their cloud was not disclosed, potentially resulting in differences when conducting measurements with future releases of Loihi 2. Furthermore, due to the runtime limitation of 20 minutes for jobs on Intel’s cloud, on-chip training was not possible, restricting the exploration of this important capability of Loihi.
The cloud interface plays a key role, as it impacts the transfer of spiking signals to the chipset. High input size may span long per-step processing time. For example, in the flexible payload use case, the execution time per example increased from approximately 5 ms to 100 ms when the input size went from 252 neurons to 299 neurons.
VI Conclusion
While we enter the era of AI, it becomes evident that energy consumption is a limiting factor when training and implementing neural networks with significant number of neurons. This issue becomes particularly relevant for nonterrestrial communication devices, such as satellite payloads, which are in need of more efficient hardware components in order to benefit from the potential of AI techniques.
Neuromorphic processors, such as Intel’s Loihi 2, have shown to be more efficient when processing individual data samples and are, therefore, a better fit for use cases where real world data arrives to the chip and it needs to be processed right away. In this article, we verified this hypothesis using real standard processor solutions, such as the Xilinx’s VCK5000 and the Intel’s Loihi 2 chipset.
Acknowledgments
This work has been supported by the European Space Agency (ESA) funded under Contract No. 4000137378/22/UK/ND - The Application of Neuromorphic Processors to Satcom Applications. Please note that the views of the authors of this paper do not necessarily reflect the views of ESA. Furthermore, this work was partially supported by the Luxembourg National Research Fund (FNR) under the project SmartSpace (C21/IS/16193290).”
The first Fact is that it confirms that Loihi 1 & 2 are most definitely still only research platforms.
The second Fact is that the lack of willingness of Intel to disclose the Cloud interphase it uses would as the paper suggests be a significant limitation for commercial adoption.
The third Fact disclosed that inference time increased on Loihi 2 the greater the number of neurons in use means is a huge issue for Intel as from every thing I have read about AKIDA the more nodes hence neurons in play the faster the inference times. (Perhaps I miss the point here so this needs a Diogenese ruler run over my conclusion.)
Fact four even Loihi 2 despite its limitations is far more efficient than Xilinx’s VCK5000 running CNN’s.
Finally Fact five using neuromorphic computing for cognitive communication is clearly the way forward.
My opinion only DYOR
Fact Finder
This company isn't a information company for the stock market, I feel ever since the Mercedes announcement the current management have put a lid on everything, watch the Financials and the PartnershipsYou have to double it.
If one were to criticize the article, one would have to say that Flor Ortiz cocked up badly in:https://arxiv.org/html/2401.06911v1
"Furthermore, due to the runtime limitation of 20 minutes for jobs on Intel’s cloud, on-chip training was not possible, restricting the exploration of this important capability of Loihi".
Akida can solve that.

Wow! Love fact five, FF sounds good to me.Hi JB
This is an important find. I have taken the following extract to cover the facts you have revealed:
Regarding the digital beamforming performance for fast-moving users, we compared the conventional LASSO solution provided by CVX [13] running on Matlab with the solution of S-LCA on Intel’s Lava simulator. Firstly, it is worth highlighting that the proposed beamforming formulation yielded sparse beamforming vectors, with both solutions being able to turn off up to 60% of the RF chains without compromising the resulting beampatterns. Regarding performance comparisons between the two solutions, both generated satisfactory beampatterns with the main lobe pointing toward the aircraft. For a numerical comparison, the beamformer’s average output power was considered as key performance indicator to assess the beamforming capabilities to mitigate the effects of noise and interference while focusing on the desired signal direction. In this context, the S-LCA solution was able to reach lower levels of beamformer’s average output power, around 19% below the value reached by the CVX solution, but with a much higher spreading of values, around 4 times higher than the CVX solution, when comparing the lower and upper quartiles of beamformer’s average output power.
- •
Superiority of SNN and Loihi 2: The results highlight that, in all cases, Intel’s Loihi 2 performs better than the CNN implemented in Xilinx’s VCK5000. However, it is worth noting that, as the batch size increases, the advantage of Loihi became less pronounced as the performance points move closer to the EDP line, although it still outperforms the Xilinx’s VCK5000 implementation.- •
Interference detection as a promising use case: Among the considered scenarios, it seems that the interference detection and classification benefited the most from the implementation on Intel’s Loihi chipset. Even though the time ratio remained generally higher than one, the energy savings achieved with Loihi were significant. In some cases, the energy ratio reached values as high as 105- •
SNN encoding: Fig. 3 compares the impact of FFT Rate and FFT TEM encoding for the ID scenario. Interestingly, the type of coding used did not have a significant impact on this comparison.- •
RRM’s Performance: While RRM did not achieve energy savings as pronounced as in the ID scenario, it consistently achieved an energy ratio exceeding 102
V-ARemarks about the results obtained with Intel’s Loihi 2
The results presented in this article were conducted with Loihi 2 but using the remote access from Intel’s research cloud. Although Intel offers the possibility of shipping physical chips to INRC partners premises, at the moment of developing these results the primary access to Loihi 2 was through the Intel’s neuromorphic research cloud. Obviously, the remote access introduced some additional limitations as it was not possible to control for concurrent usage by other users, which could lead to delays and increased power consumption. Additionally, the specific interface used by Intel on their cloud was not disclosed, potentially resulting in differences when conducting measurements with future releases of Loihi 2. Furthermore, due to the runtime limitation of 20 minutes for jobs on Intel’s cloud, on-chip training was not possible, restricting the exploration of this important capability of Loihi.
The cloud interface plays a key role, as it impacts the transfer of spiking signals to the chipset. High input size may span long per-step processing time. For example, in the flexible payload use case, the execution time per example increased from approximately 5 ms to 100 ms when the input size went from 252 neurons to 299 neurons.
VI Conclusion
While we enter the era of AI, it becomes evident that energy consumption is a limiting factor when training and implementing neural networks with significant number of neurons. This issue becomes particularly relevant for nonterrestrial communication devices, such as satellite payloads, which are in need of more efficient hardware components in order to benefit from the potential of AI techniques.
Neuromorphic processors, such as Intel’s Loihi 2, have shown to be more efficient when processing individual data samples and are, therefore, a better fit for use cases where real world data arrives to the chip and it needs to be processed right away. In this article, we verified this hypothesis using real standard processor solutions, such as the Xilinx’s VCK5000 and the Intel’s Loihi 2 chipset.
Acknowledgments
This work has been supported by the European Space Agency (ESA) funded under Contract No. 4000137378/22/UK/ND - The Application of Neuromorphic Processors to Satcom Applications. Please note that the views of the authors of this paper do not necessarily reflect the views of ESA. Furthermore, this work was partially supported by the Luxembourg National Research Fund (FNR) under the project SmartSpace (C21/IS/16193290).”
The first Fact is that it confirms that Loihi 1 & 2 are most definitely still only research platforms.
The second Fact is that the lack of willingness of Intel to disclose the Cloud interphase it uses would as the paper suggests be a significant limitation for commercial adoption.
The third Fact disclosed that inference time increased on Loihi 2 the greater the number of neurons in use means is a huge issue for Intel as from every thing I have read about AKIDA the more nodes hence neurons in play the faster the inference times. (Perhaps I miss the point here so this needs a Diogenese ruler run over my conclusion.)
Fact four even Loihi 2 despite its limitations is far more efficient than Xilinx’s VCK5000 running CNN’s.
Finally Fact five using neuromorphic computing for cognitive communication is clearly the way forward.
My opinion only DYOR
Fact Finder
Yeah it runs on 30 watts of power making it 30-30000 times more power hungry - really great for reduced power at the edge!! BrainChip had a previous relationship with Xilinx in 2017. It seems like that hasn’t translated into any meaningful advantage to AMD yet.Accelerated AI Inferencing for Space Applications with new AMD Versal AI Edge Adaptive SoC
AMD is extending its leadership in radiation-tolerant, space-grade adaptive compute solutions with the announcement of the Versal™ AI Edge XQRVE2302, the second device in the Versal adaptive SoC portfolio to be qualified for space flight. The XQRVE2302 is the first time we’ve offered an adaptive...community.amd.com
There's quite a bit mentioned about AI inferencing for AMD's Versal line up of SOC's... any idea how this compares to Akida? Xilinx went for around $50 billion when AMD aquired them recently... so the Versal edge AI must have something going for it? I'd always hoped that AMD would use Akida IP... seems like they are developing their own tech though.
Afternoon Chippers ,
On the three day chart @ 1 , 2 & 3 min time duration on volume, thinking we should see some decent volume within next hour .... i shall refrain from a price guess today .
Regards,
Esq
 when volume?
when volume?Sshhh you don't want everyone knowing you will have long lost relatives turning up wanting a loan or handout and your life will be ruined just like the mega lottery winners.Isn't it time Redditt found out that Akida is the SNN in ARM's ecosystem?

 ☹
☹