Oh I'm well aware of the phrase 'sour grapes', I purposely didn't use that, preferring 'sour' to imply discontent. And he is well placed, as we all are to express disappointment. Neil may well have profited handsomely from his years in various senior management roles. Herein lies the difference between keeping perspective and being openly negative on a forum where, as a CEO, one might expect he could keep his own counsel. One person may well regard the passage of time from inception to contract a protracted and arduous one, others expect results quickly, they need to see progress. That's fair enough, but I wouldn't want to be out of the race when in 2025/26 huge corporations are jockeying for position to saddle the winner in our sphere of industry.It's called "sour grapes".....former staff member who moved himself on....yeah...nah
The team that Sean has assembled is so much stronger, dedicated and will get us over the line, that is in no way
implying previous staff weren't any good, but we have an excellent balance now, which in turn creates a stable
working environment solidified by integrity and mutual respect.....just saying.
Tech.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
BRN Discussion Ongoing
- Thread starter TechGirl
- Start date
Bravo
Meow Meow 🐾
1.55 mins - Ola Källenius
"Absolutely the most intelligent car that we have ever made. Supercomputer on board, sensors everywhere, artificial intelligence-based software. It feels like this is the complete package."
3.55 mins - Ola Källenius
"This is MBOS. Mercedes Benz Operating System. It's full first version, so every digital feature you could possibly ever think of, you'll probably find in this car."
View attachment 72565
This video is included in the article.
The new E-class is due to go on sale in 2025, so I guess it won't be too long before we find out if our technology is involved in some way, shape or form, whether that is via TENNs being included in the software or what not.
Ola Källenius said this "is the most intelligent car that we have ever made", which makes me think that it has to be at least as intelligent as the EQXX.
The article I posted a link to a little earlier also states the following.
Ola Källenius also refers to the new MBOS in the video when he demos the voice assistant. If you look at this article below dated 22 Jan 2024 in eMercedesBenz, it talks about the MBOS having been derived from the display technology in the EQXX.
Extract

Redefining the Road: Exploring the Mercedes-Benz Concept CLA Coupe | eMercedesBenz
Electrifying Elegance: Mercedes-Benz Concept CLA Coupe Redefines Sustainable Luxury
emercedesbenz.com
And we all know that the UI/UX display technology in the EQXX incorporated our very own brain mimicking tech.


Mercedes-Benz VISION EQXX demonstrates its world-beating efficiency in real world driving
Successful first road trip takes electric vehicle efficiency to a new level Stuttgart/Cassis. The VISION EQXX from Mercedes-Benz has now taken to the roads of Europe and has demonstrated its outstanding range and efficiency.
Attachments

Last edited:
Ronaldi is a previous NED I think so it’s not a good look for BRNSomeone is not thanking BrainChip it's Friday.
View attachment 72559
Bravo
Meow Meow 🐾
The new E-class is due to go on sale in 2025, so I guess it won't be too long before we find out if our technology is involved in some way, shape or form, whether that is via TENNs being included in the software or what not.
Ola Källenius said this "is the most intelligent car that we have ever made", which makes me think that it has to be at least as intelligent as the EQXX.
The article I posted a link to a little earlier also states the following.
View attachment 72578
Ola Källenius also refers to the new MBOS in the video when he demos the voice assistant. If you look at this article below dated 22 Jan 2024 in eMercedesBenz, it talks about the MBOS having been derived from the display technology in the EQXX.
View attachment 72577
Extract
View attachment 72576
Redefining the Road: Exploring the Mercedes-Benz Concept CLA Coupe | eMercedesBenz
Electrifying Elegance: Mercedes-Benz Concept CLA Coupe Redefines Sustainable Luxuryemercedesbenz.com
And we all know that the UI/UX display technology in the EQXX incorporated our very own brain mimicking tech.
View attachment 72579

Mercedes-Benz VISION EQXX demonstrates its world-beating efficiency in real world driving
Successful first road trip takes electric vehicle efficiency to a new level Stuttgart/Cassis. The VISION EQXX from Mercedes-Benz has now taken to the roads of Europe and has demonstrated its outstanding range and efficiency.www.linkedin.com
And in addition to all of the above there's also this, which I literally just stumbled across, like 30 seconds ago.
OMG! Great work Kimberley! I think I'm going to faint!
Here's a question and answer session that I just undertook with myself.
Question: How likely is it that Magnus Ostberg would thank someone for remarking on "brain inspired" software if there is no brain inspired software?
Answer: Not bloody likely IMO.
Last edited:
D
Deleted member 3781
Guest
You know … now we know who T&J is… really… this is so unprofessional… ridiculous behaviour to post something like that in a forum which is build to make business connections… this is disqualifying him and maybe it’s critical for his current position better for him to delete itRonaldi is a previous NED I think so it’s not a good look for BRN
"Stay tuned"!!!And in addition to all of the above there's also this, which I literally just stumbled across, like 30 seconds ago.
OMG! I think I'm going to faint!
View attachment 72581
View attachment 72580
D
Deleted member 3781
Guest
Nice close! 29 cent… I thought we go maybe 27,5 / 28…
ndefries
Regular
he was hardly a Director of Brainchip. He had that title around the time that there was a reverse takeout or whatever it was and he pretty much left at the next AGM. He has had zero involvement.You know … now we know who T&J is… really… this is so unprofessional… ridiculous behaviour to post something like that in a forum which is build to make business connections… this is disqualifying him and maybe it’s critical for his current position better for him to delete it
Pom down under
Top 20
What a nice feeling to go to work and come home to find out your richer on paper than when you left. Have a great weekend everyone.

sleepymonk
Regular
With due respect, no offense intendedYou know … now we know who T&J is… really… this is so unprofessional… ridiculous behaviour to post something like that in a forum which is build to make business connections… this is disqualifying him and maybe it’s critical for his current position better for him to delete it
1: Really? a former NED venting out his frustration is something you believe unprofessional? He obviously has his skin attached to our beloved BRN, That is why he has every right to express his own opinion with or without inside info
2: We had our director Pia selling her shares right after Sean exploding his confidence and our chairman stating he can't wait to join her on any boards in the AGM, don't forget, she sold before the CR. I, SPEAKING FOR MYSELF ONLY, DO NOT BELIEVE THIS IS RIGHT.
3: CR, as a reference here though, which was denied in our last AGM, came out as a surprise (at least to me) at the almost lowest SP 19.3C, DOES THIS RING THE BELL?
4: I am absolutely shocked and embarrassed when someone could even dare to claim that he built a better team and ecosystem in comparison to a less competitive team, not so competitive product line but landing 2, yes two, IP LICENCES. THIS IS BEYOND MY DOT LINE
IN SHORT, I DO NOT BELIEVE SEAN IS CAPABLE OF DOING HIS JOB AT ALL.
Pom down under
Top 20
1.55 mins - Ola Källenius
"Absolutely the most intelligent car that we have ever made. Supercomputer on board, sensors everywhere, artificial intelligence-based software. It feels like this is the complete package."
3.55 mins - Ola Källenius
"This is MBOS. Mercedes Benz Operating System. It's full first version, so every digital feature you could possibly ever think of, you'll probably find in this car."
This video is included in the article.

Mercedes CEO Drives 2026 Electric CLA, Reveals AI Assistant And 2-Speed Transmission | Carscoops
Mercedes CEO Ola Källenius jumps behind the wheel of next year’s CLA and drops a few hints about the Tesla Model 3 rivalwww.carscoops.com
Pom down under
Top 20
With due respect, no offense intended
1: Really? a former NED venting out his frustration is something you believe unprofessional? He obviously has his skin attached to our beloved BRN, That is why he has every right to express his own opinion with or without inside info
2: We had our director Pia selling her shares right after Sean exploding his confidence and our chairman stating he can't wait to join her on any boards in the AGM, don't forget, she sold before the CR. I, SPEAKING FOR MYSELF ONLY, DO NOT BELIEVE THIS IS RIGHT.
3: CR, as a reference here though, which was denied in our last AGM, came out as a surprise (at least to me) at the almost lowest SP 19.3C, DOES THIS RING THE BELL?
4: I am absolutely shocked and embarrassed when someone could even dare to claim that he built a better team and ecosystem in comparison to a less competitive team, not so competitive product line but landing 2, yes two, IP LICENCES. THIS IS BEYOND MY DOT LINE
IN SHORT, I DO NOT BELIEVE SEAN IS CAPABLE OF DOING HIS JOB AT ALL.
He was likely saying thanks for the Go Mercedes remarks from the student at self employed (so a nobody).And in addition to all of the above there's also this, which I literally just stumbled across, like 30 seconds ago.
OMG! Great work Kimberley! I think I'm going to faint!
Here's a question and answer session that I just undertook with myself.
Question: How likely is it that Magnus Ostberg would thank someone for remarking on "brain inspired" software if there is no brain inspired software?
Answer: Not bloody likely IMO.
View attachment 72581
View attachment 72580
I think your dot joing in this case is completely over optimistic.
D
Deleted member 3781
Guest
You know… you stated it right… a “former” who is frustrated… why should he be frustrated? He has nothing to do with brainchip anymore… look what he do with his new company.. he should care more about that. And I think it’s unprofessional to speak out his feelings on LinkedIn. This is childish. And I don’t see frustration because brainchip is doing not well.. I more see that he is trying to badmouth the company and Sean. I bet he is a shorter or at least just an DHWith due respect, no offense intended
1: Really? a former NED venting out his frustration is something you believe unprofessional? He obviously has his skin attached to our beloved BRN, That is why he has every right to express his own opinion with or without inside info
2: We had our director Pia selling her shares right after Sean exploding his confidence and our chairman stating he can't wait to join her on any boards in the AGM, don't forget, she sold before the CR. I, SPEAKING FOR MYSELF ONLY, DO NOT BELIEVE THIS IS RIGHT.
3: CR, as a reference here though, which was denied in our last AGM, came out as a surprise (at least to me) at the almost lowest SP 19.3C, DOES THIS RING THE BELL?
4: I am absolutely shocked and embarrassed when someone could even dare to claim that he built a better team and ecosystem in comparison to a less competitive team, not so competitive product line but landing 2, yes two, IP LICENCES. THIS IS BEYOND MY DOT LINE
IN SHORT, I DO NOT BELIEVE SEAN IS CAPABLE OF DOING HIS JOB AT ALL.

Bravo
Meow Meow 🐾
Completely understand and of course your entitled to your opinion.He was likely saying thanks for the Go Mercedes remarks from the student at self employed (so a nobody).
I think your dot joing in this case is completely over optimistic.
My take on it is that that the term "brain inspired software" is really quite specific. Magnus would know exactly what that refers to given the MBOS was derived from the display technology in the EQXX which featured brain inspired technology.
Was he merely being polite in responding (despite it having the potential to mislead) or was he giving an indication as to the actual nature of the software itself? I guess we'll find out soon enough. As Magnus says "stay tuned".
Pom down under
Top 20
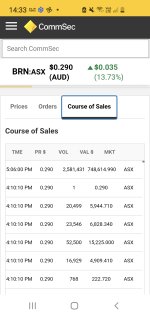
Just some loose change I found behind the sofaHoly cow that's a big trade! Is that even legal after hours, I have no clue so asking for a friend.
Yoda
Regular
Based on the Vision EQXX and "include Artificial Intelligence that mimics the way the human brain works.". That's as big a hint as we've had for a very long time that they have used Akida. I can't really see what else this could be given the Vision EQXX used Akida. Looks like MB is delivering on what they said after all (delivering new models based on the EQXX). This is exciting.The new E-class is due to go on sale in 2025, so I guess it won't be too long before we find out if our technology is involved in some way, shape or form, whether that is via TENNs being included in the software or what not.
Ola Källenius said this "is the most intelligent car that we have ever made", which makes me think that it has to be at least as intelligent as the EQXX.
The article I posted a link to a little earlier also states the following.
View attachment 72578
Ola Källenius also refers to the new MBOS in the video when he demos the voice assistant. If you look at this article below dated 22 Jan 2024 in eMercedesBenz, it talks about the MBOS having been derived from the display technology in the EQXX.
View attachment 72577
Extract
View attachment 72576
Redefining the Road: Exploring the Mercedes-Benz Concept CLA Coupe | eMercedesBenz
Electrifying Elegance: Mercedes-Benz Concept CLA Coupe Redefines Sustainable Luxuryemercedesbenz.com
And we all know that the UI/UX display technology in the EQXX incorporated our very own brain mimicking tech.
View attachment 72579
Mercedes-Benz VISION EQXX demonstrates its world-beating efficiency in real world driving
Successful first road trip takes electric vehicle efficiency to a new level Stuttgart/Cassis. The VISION EQXX from Mercedes-Benz has now taken to the roads of Europe and has demonstrated its outstanding range and efficiency.
Similar threads
- Replies
- 3
- Views
- 12K
D
- Replies
- 0
- Views
- 5K
- Replies
- 9
- Views
- 6K
- Replies
- 0
- Views
- 3K