D
Deleted member 118
Guest

Intel is running rings around AMD and Arm at the edge
What will it take to loosen the x86 giant's edge stranglehold?
Think akida can run up to 80 nodes?
I have often thought about this and wanted to write about it in detail. It's perfectly normal for companies to want to sell their success and ingenious new technology as their own. I'm getting used to that, or I already am.Morning Chippers,
Having a read of a weekend financial newspaper...
FULL PAGE advert from Mercedes-Benz.
* with a picture of the single panel glass dashboard floating above a Mercedes and a young lass looking up at the panel in wonderment.
* the caption at bottom of picture reads....
As innovative as it is intuitive: the Mercedes-Benz MBUX Hyperscreen with artificial intelligence.
INNOVATIONS BY
( Mercedes-Benz logo ).
* At the top of the advert , in very small print....
Overseas model showen. Vehicle showen not currently available in Australia.
Apart from what we all know here, there is no mention of Brainchip in the advert.
Getting closer by the day.
Regards,
Esq.
Pretty standard advertising where no one wants to reveal the ingredients of the recipe.Morning Chippers,
Having a read of a weekend financial newspaper...
FULL PAGE advert from Mercedes-Benz.
* with a picture of the single panel glass dashboard floating above a Mercedes and a young lass looking up at the panel in wonderment.
* the caption at bottom of picture reads....
As innovative as it is intuitive: the Mercedes-Benz MBUX Hyperscreen with artificial intelligence.
INNOVATIONS BY
( Mercedes-Benz logo ).
* At the top of the advert , in very small print....
Overseas model showen. Vehicle showen not currently available in Australia.
Apart from what we all know here, there is no mention of Brainchip in the advert.
Getting closer by the day.
Regards,
Esq.

We have long been looking for official confirmation of a successful NASA Vorago Brainchip Phase 1 project.
Well I have found it and it is copied with a link below.
Note:
1. Vorago is Silicon Space Technology Corporation for newer shareholders.
2. Vorago used the term CNN RNN to describe AKIDA not SCNN.
As you read through the extracts you will note the following:
A. Vorago met all of the Phase 1 objectives
B. Vorago has five letters in support of continuing to the next Phase 2 importantly/interestingly two of these letters offer funding for the Phase 2 independent of NASA - (I personally am thinking large Aerospace companies jumping on board)
C. Vorago has modelling which shows AKIDA will allow NASA to have autonomous Rovers that will achieve speeds of up to 20 kph compared with a present speed of 4 centimetres a second.
There is in my opinion no other company on this planet with technology that can compete with the creation of Peter van der Made and Anil Mankar.
The Original Phase 1:
"The ultimate goal of this project is to create a radiation-hardened Neural Network suitable for Ede use. Neural Networks operating at the Edge will need to perform Continuous Learning and Few-shot/One-shot Learning with very low energy requirements, as will NN operation. Spiking Neural Networks (SNNs) provide the architectural framework to enable Edge operation and Continuous Learning. SNNs are event-driven and represent events as a spike or a train of spikes. Because of the sparsity of their data representation, the amount of processing Neural Networks need to do for the same stimulus can be significantly less than conventional Convolutional Neural Networks (CNNs), much like a human brain. To function in Space and in other extreme Edge environments, Neural Networks, including SNNs, must be made rad-hard.Brainchip’s Akida Event Domain Neural Processor (www.brainchipinc.com) offers native support for SNNs. Brainchip has been able to drive power consumption down to about 3 pJ per synaptic operation in their 28nm Si implementation. The Akida Development Environment (ADE) uses industry-standard development tools Tensorflow and Keras to allow easy simulation of its IP.Phase I is the first step towards creating radiation-hardened Edge AI capability. We plan to use the Akida Neural Processor architecture and, in Phase I, will: Understand the operation of Brainchip’s IP Understand 28nm instantiation of that IP (Akida) Evaluate radiation vulnerability of different parts of the IP through the Akida Development Environment Define architecture of target IC Define how HARDSIL® will be used to harden each chosen IP block Choose a target CMOS node (likely 28nm) and create a plan to design and fabricate the IC in that node, including defining the HARDSIL® process modules for this baseline process Define the radiation testing plan to establish the radiation robustness of the ICSuccessfully accomplishing these objectives:Establishes the feasibility of creating a useful, radiation-hardened product IC with embedded NPU and already-existing supporting software ecosystem to allow rapid adoption and productive use within NASA and the Space community.\n\n\n\n\t Creates the basis for an executable Phase II proposal and path towards fabrication of the processor."
CNN RNN Processor
FIRM: SILICON SPACE TECHNOLOGY CORPORATION PI: Jim Carlquist Proposal #:H6.22-4509
NON-PROPRIETARY DATA
Objectives:
The goal of this project is the creation of a radiation-hardened Spiking Neural Network (SNN) SoC based on the BrainChip Akida Neuron Fabric IP. Akida is a member of a small set of existing SNN architectures structured to more closely emulate computation in a human brain. The rationale for using a Spiking Neural Network (SNN) for Edge AI Computing is because of its efficiencies. The neurmorphic approach used in the Akida architecture takes fewer MACs per operation since it creates and uses sparsity of both weights and activation by its event-based model. In addition, Akida reduces memory consumption by quantizing and compressing network parameters. This also helps to reduce power consumption and die size while maintaining performance.
Spiking Neural Network Block Diagram
ACCOMPLISHMENTS
Notable Deliverables Provided:
• Design and Manufacturing Plans
• Radiation Testing Plan (included in Final report)
• Technical final report
Key Milestones Met
• Understand Akida Architecture
• Understand 28nm Implementation
• Evaluate Radiation Vulnerability of the IP Through the Akida
Development Environment
• Define Architecture of Target IC
• Define how HARDSIL® will be used in Target IC
• Create Design and Manufacturing Plans
• Define the Radiation Testing Plan to Establish the Radiation
Robustness of the IC
FUTURE PLANNED DEVELOPMENTS
Planned Post-Phase II Partners
We received five Letters of Support for this project.
Two of which will provide capital infusion to keep the project going, one for aid in radiation testing, and the final two for use in future space flights.
Planned/Possible Mission Infusion
NASA is keen to increase the performance of its autonomous rovers to allow for greater speeds.
Current routing methodologies limit speeds to 4cm/sec while NASA has a goal to be able to have autonomous rovers traverse at speeds up to 20km/hr.
Early calculations show the potential for this device to process several of the required neural network algorithms fast enough to meet this goal.
Planned/Possible Mission Commercialization
A detailed plan is included in the Phase I final submittal to commercialized a RADHARD flight ready QML, SNN SoC to be available for NASA and commercial use.
This plan will include a Phase II plus extensions to reach the commercialization goals we are seeking.
CONTRACT (CENTER): SUBTOPIC:
SOLICITATION-PHASE: TA:
80NSSC20C0365 (ARC)
H6.22 Deep Neural Net and Neuromorphic Processors for In- Space Autonomy and Cognition
SBIR 2020-I4.5.0 Autonomy
My opinion only DYOR
FF
AKIDA BALLISTA
Originally posted in a NASA thread by @uiux but now has greater significance:
Proposal Summary
Proposal Information
Proposal Number:
21-2- H6.22-1743
Phase 1 Contract #:
80NSSC21C0233
Subtopic Title:
Deep Neural Net and Neuromorphic Processors for In-Space Autonomy and Cognition
Proposal Title:
Neuromorphic Enhanced Cognitive Radio
Small Business Concern
Firm: Intellisense Systems, Inc.
Address:
21041 South Western Avenue, Torrance, CA 90501
Phone:
(310) 320-1827
Principal Investigator:
Name:
Mr. Wenjian Wang Ph.D.
E-mail:
wwang@intellisenseinc.com
Address:
21041 South Western Avenue, CA 90501 - 1727
Phone: (310) 320-1827
Business Official:
Name: Selvy Utama
E-mail:
notify@intellisenseinc.com
Address:
21041 South Western Avenue, CA 90501 - 1727
Phone: (310) 320-1827
Summary Details:
Estimated Technology Readiness Level (TRL) :
Begin: 3
End: 4
Technical Abstract (Limit 2000 characters, approximately 200 words):
Intellisense Systems, Inc. proposes in Phase II to advance development of a Neuromorphic Enhanced Cognitive Radio (NECR) device to enable autonomous space operations on platforms constrained by size, weight, and power (SWaP). NECR is a low-size, -weight, and -power (-SWaP) cognitive radio built on the open-source framework, i.e., GNU Radio and RFNoC™, with new enhancements in environment learning and improvements in transmission quality and data processing. Due to the high efficiency of spiking neural networks and their low-latency, energy-efficient implementation on neuromorphic computing hardware, NECR can be integrated into SWaP-constrained platforms in spacecraft and robotics, to provide reliable communication in unknown and uncharacterized space environments such as the Moon and Mars. In Phase II, Intellisense will improve the NECR system for cognitive communication capabilities accelerated by neuromorphic hardware. We will refine the overall NECR system architecture to achieve cognitive communication capabilities accelerated by neuromorphic hardware, on which a special focus will be the mapping, optimization, and implementation of smart sensing algorithms on the neuromorphic hardware. The Phase II smart sensing algorithm library will include Kalman filter, Carrier Frequency Offset estimation, symbol rate estimation, energy detection- and matched filter-based spectrum sensing, signal-to-noise ratio estimation, and automatic modulation identification.
These algorithms will be implemented on COTS neuromorphic computing hardware such as Akida processor from BrainChip, and then integrated with radio frequency modules and radiation-hardened packaging into a Phase II prototype.
At the end of Phase II, the prototype will be delivered to NASA for testing and evaluation, along with a plan describing a path to meeting fault and tolerance requirements for mission deployment and API documents for integration with CubeSat, SmallSat, and 'ROVER' for flight demonstration.
Potential NASA Applications (Limit 1500 characters, approximately 150 words):
NECR technology will have many NASA applications due to its low-SWaP and low-cost cognitive sensing capability. It can be used to enhance the robustness and reliability of space communication and networking, especially cognitive radio devices. NECR can be directly transitioned to the Human Exploration and Operations Mission Directorate (HEOMD) Space Communications and Navigation (SCaN) Program, CubeSat, SmallSat, and 'ROVER' to address the needs of the Cognitive Communications project.
Potential Non-NASA Applications (Limit 1500 characters, approximately 150 words):
NECR technology’s low-SWaP and low-cost cognitive sensing capability will have many non-NASA applications. The NECR technology can be integrated into commercial communication systems to enhance cognitive sensing and communication capability. Automakers can integrate the NECR technology into automobiles for cognitive sensing and communication.
Duration: 24
Looks like Intellisense do a lot of work with all forms of US defence forces.Originally posted in a NASA thread by @uiux but now has greater significance:
Proposal Summary
Proposal Information
Proposal Number:
21-2- H6.22-1743
Phase 1 Contract #:
80NSSC21C0233
Subtopic Title:
Deep Neural Net and Neuromorphic Processors for In-Space Autonomy and Cognition
Proposal Title:
Neuromorphic Enhanced Cognitive Radio
Small Business Concern
Firm: Intellisense Systems, Inc.
Address:
21041 South Western Avenue, Torrance, CA 90501
Phone:
(310) 320-1827
Principal Investigator:
Name:
Mr. Wenjian Wang Ph.D.
E-mail:
wwang@intellisenseinc.com
Address:
21041 South Western Avenue, CA 90501 - 1727
Phone: (310) 320-1827
Business Official:
Name: Selvy Utama
E-mail:
notify@intellisenseinc.com
Address:
21041 South Western Avenue, CA 90501 - 1727
Phone: (310) 320-1827
Summary Details:
Estimated Technology Readiness Level (TRL) :
Begin: 3
End: 4
Technical Abstract (Limit 2000 characters, approximately 200 words):
Intellisense Systems, Inc. proposes in Phase II to advance development of a Neuromorphic Enhanced Cognitive Radio (NECR) device to enable autonomous space operations on platforms constrained by size, weight, and power (SWaP). NECR is a low-size, -weight, and -power (-SWaP) cognitive radio built on the open-source framework, i.e., GNU Radio and RFNoC™, with new enhancements in environment learning and improvements in transmission quality and data processing. Due to the high efficiency of spiking neural networks and their low-latency, energy-efficient implementation on neuromorphic computing hardware, NECR can be integrated into SWaP-constrained platforms in spacecraft and robotics, to provide reliable communication in unknown and uncharacterized space environments such as the Moon and Mars. In Phase II, Intellisense will improve the NECR system for cognitive communication capabilities accelerated by neuromorphic hardware. We will refine the overall NECR system architecture to achieve cognitive communication capabilities accelerated by neuromorphic hardware, on which a special focus will be the mapping, optimization, and implementation of smart sensing algorithms on the neuromorphic hardware. The Phase II smart sensing algorithm library will include Kalman filter, Carrier Frequency Offset estimation, symbol rate estimation, energy detection- and matched filter-based spectrum sensing, signal-to-noise ratio estimation, and automatic modulation identification.
These algorithms will be implemented on COTS neuromorphic computing hardware such as Akida processor from BrainChip, and then integrated with radio frequency modules and radiation-hardened packaging into a Phase II prototype.
At the end of Phase II, the prototype will be delivered to NASA for testing and evaluation, along with a plan describing a path to meeting fault and tolerance requirements for mission deployment and API documents for integration with CubeSat, SmallSat, and 'ROVER' for flight demonstration.
Potential NASA Applications (Limit 1500 characters, approximately 150 words):
NECR technology will have many NASA applications due to its low-SWaP and low-cost cognitive sensing capability. It can be used to enhance the robustness and reliability of space communication and networking, especially cognitive radio devices. NECR can be directly transitioned to the Human Exploration and Operations Mission Directorate (HEOMD) Space Communications and Navigation (SCaN) Program, CubeSat, SmallSat, and 'ROVER' to address the needs of the Cognitive Communications project.
Potential Non-NASA Applications (Limit 1500 characters, approximately 150 words):
NECR technology’s low-SWaP and low-cost cognitive sensing capability will have many non-NASA applications. The NECR technology can be integrated into commercial communication systems to enhance cognitive sensing and communication capability. Automakers can integrate the NECR technology into automobiles for cognitive sensing and communication.
Duration: 24
Thanks for your input and your usual well formulated response's ............. I for one am expecting a '' teaser'' increase in Co revenue commencing from this upcoming 4C in the region of say ~$500k to ~$1 million .......... I hope the funds will start to come in from a current existing client the like's of someone like "Socionext" to kick things off.The AGM was held basically 2/3's through the 2nd quarter.
I believe that he was referring to future quarters, meaning, being disclosed in 4C's in late October 2022 and late January 2023 for example, for the next 2 quarters.
If any material contract had taken place in April, May or June 2022, we would have been informed, maybe I'm wrong, maybe there will be
an explosion in revenue, which would be fantastic, but in my opinion, it clearly isn't coming in the reported 4C in late July 2022.
I respect your view, I'm wrong about plenty of things, and always happy to admit it.
Regards....Tech
I think we are all pretty certain that AKIDA IP isn't in the current sales line of Mercedes Benz.Morning Chippers,
Having a read of a weekend financial newspaper...
FULL PAGE advert from Mercedes-Benz.
* with a picture of the single panel glass dashboard floating above a Mercedes and a young lass looking up at the panel in wonderment.
* the caption at bottom of picture reads....
As innovative as it is intuitive: the Mercedes-Benz MBUX Hyperscreen with artificial intelligence.
INNOVATIONS BY
( Mercedes-Benz logo ).
* At the top of the advert , in very small print....
Overseas model showen. Vehicle showen not currently available in Australia.
Apart from what we all know here, there is no mention of Brainchip in the advert.
Getting closer by the day.
Regards,
Esq.
BLooks like Intellisense do a lot of work with all forms of US defence forces.
Apologies if already discussed.
Press Releases - Intellisense Systems, Inc.
A list of the latest available Press Releases here at Intellisense Systems, Inc.www.intellisenseinc.com
VictorG said:
Es gibt ein Gerücht, dass die Nasa die Akida-Flagge auf dem Mars Rover hissen wird
Translated means - there is a rumour that NASA will hoist the Akida flag on the Mars rover
(close enough to it)


Thanks FMF. it's obvious that when the US military wants the best products the money becomes available. Perhaps they'll all need an upgrade once the gang has Akida II up and running.B
Go here and start looking at diff contracts and diff keyword searches.
View attachment 10619
View attachment 10620
And there's so much going on that we may never hear about. Roll on revenue stream.And just like that, a rumour was born!
First we'll have to work out what an Akida flag looks like and whether it would be more prudent to opt for a BrainChip flag instead. And then, of course, all necessary arrangements will have to be made for it's ironing to take place in outer space prior to it's hoisting. One small step for man, one giant crease-less BrainChip flag on Mars for mankind.
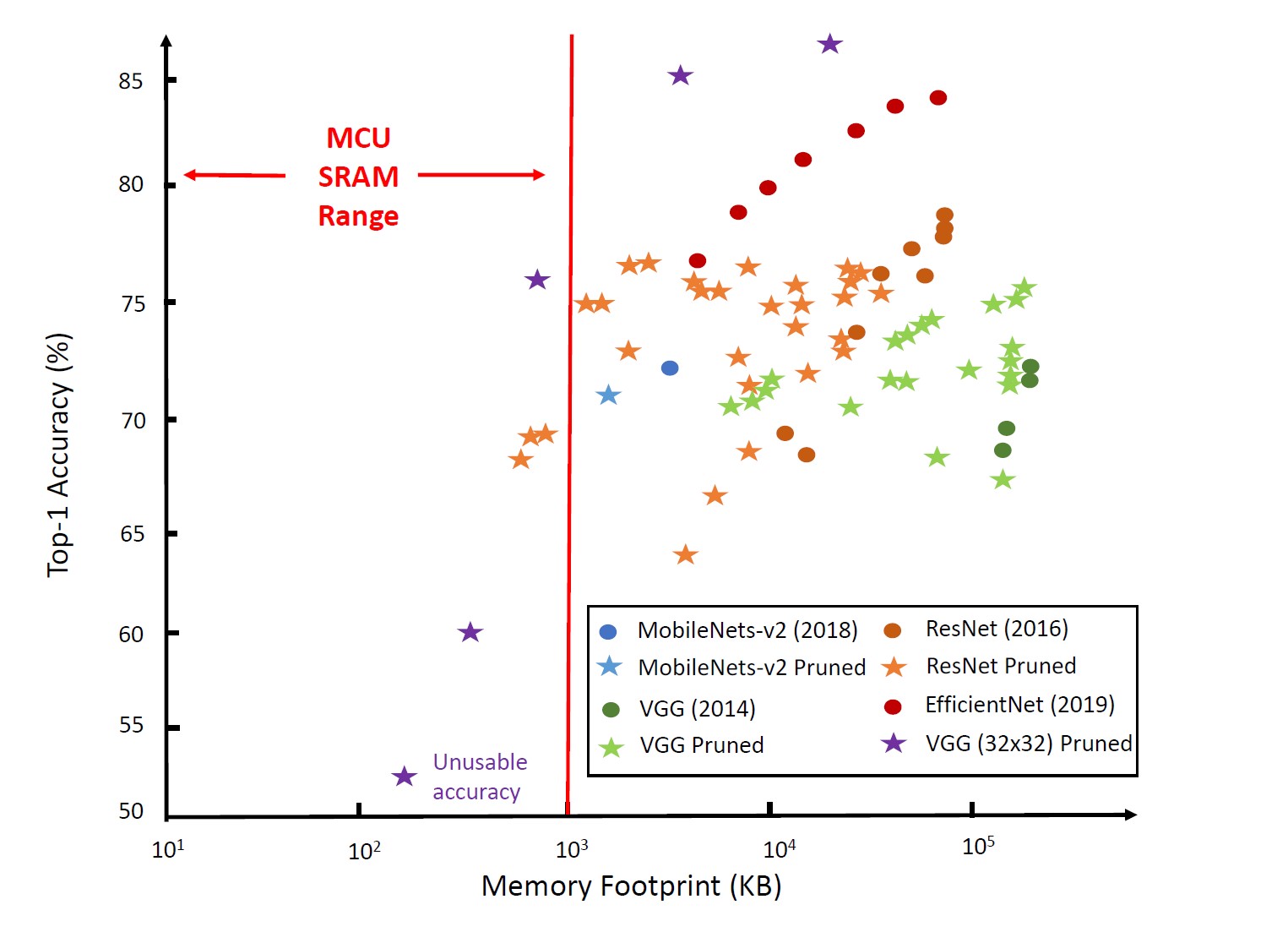 Figure 1: The available memory on most MCUs is much too small to support the needs of the majority of NNs. (Image: Arxiv)
Figure 1: The available memory on most MCUs is much too small to support the needs of the majority of NNs. (Image: Arxiv)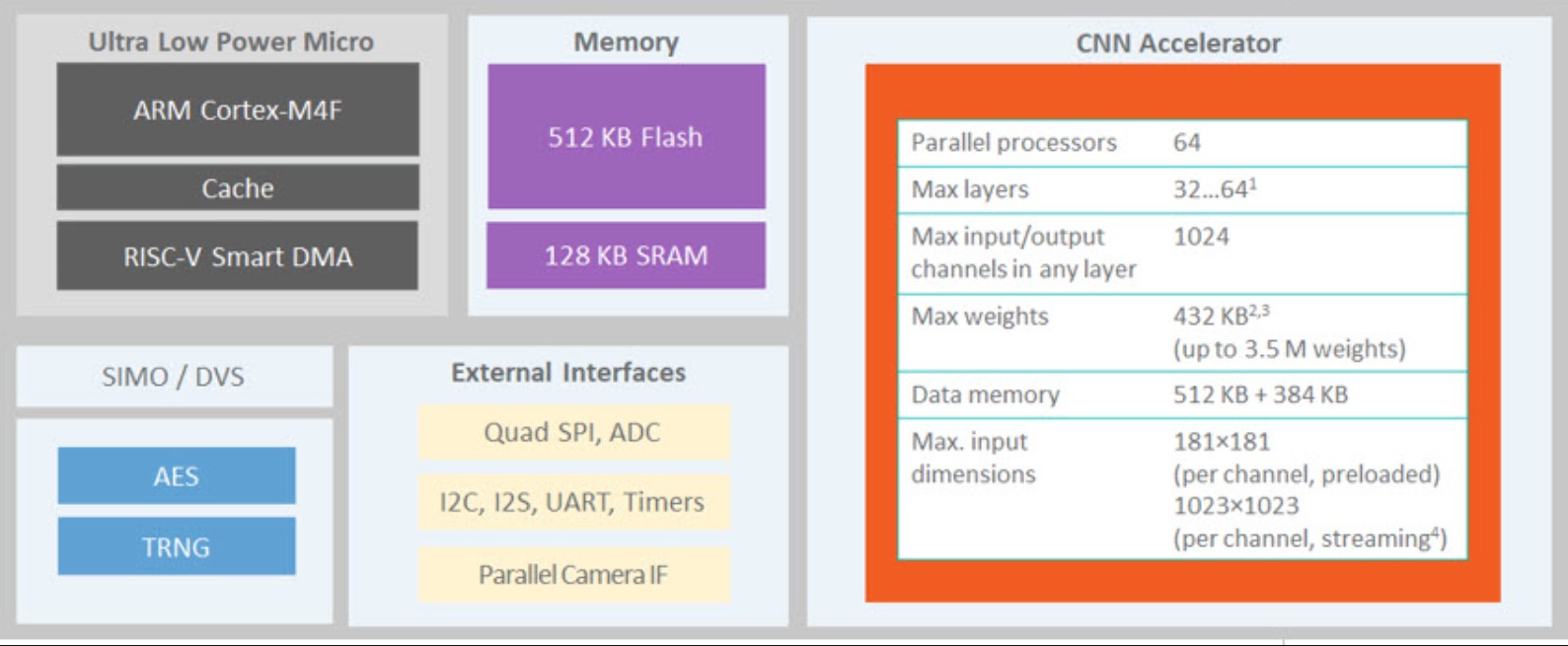 Figure 2: Neural MCU block diagram showing the basic MCU blocks (upper left) and the CNN accelerator section (right). (Image: Maxim)
Figure 2: Neural MCU block diagram showing the basic MCU blocks (upper left) and the CNN accelerator section (right). (Image: Maxim)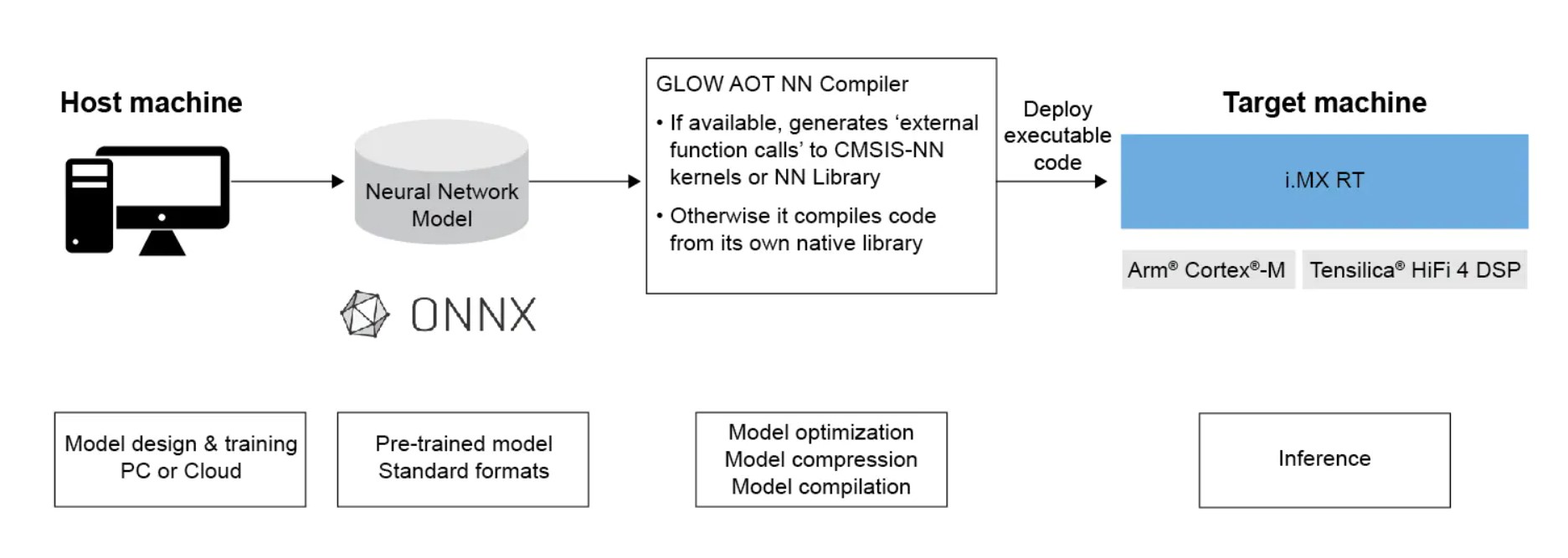 Figure 3: Example of an AOT compilation flow diagram using Glow. (Image: NXP)
Figure 3: Example of an AOT compilation flow diagram using Glow. (Image: NXP)As others nave mentioned, BRN probably won’t make a lot of money from the NASA in the grand scheme of things (short term) It’s not like NASA is going to produce 1 million rovers.This may help? Looks like we are at least recuperating our costs.
BrainChip and VORAGO Technologies Agree to Collaborate through the Akida™ Early Access Program
BrainChip and VORAGO Technologies Agree to Collaborate through the Akida™ Early Access Program
Agreement to Support Phase I of NASA Program for Radiation-Hardened Neuromorphic Processor
Aliso Viejo, California – September 2, 2020 – BrainChip Holdings Ltd (ASX: BRN), a leading provider of ultra-low power high performance AI technology, today announced that VORAGO Technologies has signed the Akida™ Early Access Program Agreement. The collaboration is intended to support a Phase I NASA program for a neuromorphic processor that meets spaceflight requirements. The BrainChip Early Access Program is available to a select group of customers that require early access to the Akida device, evaluation boards and dedicated support. The EAP agreement includes payments that are intended to offset the Company’s expenses to support partner needs.
The Akida neuromorphic processor is uniquely suited for spaceflight and aerospace applications. The device is a complete neural processor and does not require an external CPU, memory or Deep Learning Accelerator (DLA). Reducing component count, size and power consumption are paramount concerns in spaceflight and aerospace applications. The level of integration and ultra-low power performance of Akida supports these critical criteria. Additionally, Akida provides incremental learning. With incremental learning, new classifiers can be added to the network without retraining the entire network. The benefit in spaceflight and aerospace applications is significant as real-time local incremental learning allows continuous operation when new discoveries or circumstances occur.



