They are all hereThe new home feels awesome. Thanks all for the smooth transition.
I would love to see uiux barrel tech dolci and few other old good friends soon as well. Then will be happy complete happy family. Was feeling like a strangers house in own brn forum at copper.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
BRN Discussion Ongoing
- Thread starter TechGirl
- Start date
Rodney
Regular
Yes never made the board before go figureI think the Mods were so focused on the BRN forum they let one slip through to the keeper ROFL.
View attachment 401
Another BRN top rated post lol
stockduck
Regular
If you go to a bank as a customer for investing your assets there, you will be told a lot about diversification and how to put the risk of loss into perspective and mitigate it while at the same time reducing your chances of winning.
The younger you are, the more risk-oriented you can dare to invest and vice versa.
That's probably true, if you believe the experts.
But there is also another point of view of the things.
There are companies on the market, that are so globally diversified in the products they sell, that a low risk of losses in the event of economic crises can also be expected here.
For me Brainchip is such a company with this breakthrough invention Akida in neuromorphic chip technology. For the next 5 years, Brainchip will put my guess to the test.
If the dividends per share are then paid, I'll start investing in hydrogen technology and battery technology.
I assume that the large fund companies already know this and have therefore bought into Brainchip in order to diversify twice with the chance of higher profit expectations at the same time.
(No financial advice please do your own research cause I´m no financial expert!)
The younger you are, the more risk-oriented you can dare to invest and vice versa.
That's probably true, if you believe the experts.
But there is also another point of view of the things.
There are companies on the market, that are so globally diversified in the products they sell, that a low risk of losses in the event of economic crises can also be expected here.
For me Brainchip is such a company with this breakthrough invention Akida in neuromorphic chip technology. For the next 5 years, Brainchip will put my guess to the test.
If the dividends per share are then paid, I'll start investing in hydrogen technology and battery technology.
I assume that the large fund companies already know this and have therefore bought into Brainchip in order to diversify twice with the chance of higher profit expectations at the same time.
(No financial advice please do your own research cause I´m no financial expert!)
Stable Genius
Regular
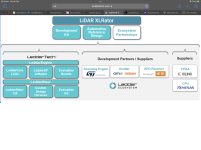
I was on the Brainchip website and found where they were discussing Xilinx and have included an excerpt:Wow that’s very exciting. I thought I had previously read Xilinx and Brainchip had worked together but my recollection had something to do with cctv video software which is off the mark.
So to try and summarise what I have learnt from other information shared today it sounds as though Akida is somehow in Valeo’s lidar technology but Luminar are supplying the actual lidar for it. And then Akida IP is possibly on Xilinix FPGA boards also being supplied to Mercedes.
I am not a tech head so I could be way off the mark but that‘s an awesome possiblity. It‘s such a tangled web. As Fact Finder said earlier it’s going to be very hard to positively identify where Akida is being used until it is announced… if it is announced because it could be anywhere.
All my opinion formed thanks to the 1000 eyes!
Cheers!
It’s under ”The challenge of building inferencing chips”. https://brainchipinc.com/challenges-of-inferencing-chips/
Speed matters
The key factor here is throughput. “These are generally plugged-in devices. Power is always critical, and there is only so much dissipation you can afford. But in the hierarchy of systems, there are other things that come before power. Memory is certainly another big component of AI inference at the edge. How much memory and how much bandwidth you can sustain?”
For companies building these chips, market opportunities are flourishing. Geoff Tate, CEO of Flex Logix, points to such markets as biomedical imaging for implementing AI in ultrasound systems, genomic systems, along with scientific imaging applications that require very high resolution and very high frame rate. Surveillance cameras for retail stores also are growing in use so retailers can extend the use of the cameras wired already into their servers to capture information such as how many customers are coming into the store, customer wait times, etc.
While many, if not most, inferencing chips are mainly CPU-based, Flex Logix uses some embedded FPGA technology in its inferencing chip. “Companies like Microsoft use FPGAs in their datacenter today. They’ve deployed FPGAs for some time. They’ve done it because they found workloads that are common in their datacenter for which they can write code that runs on the FPGA, and basically it will run faster at lower cost and power than if it ran on a processor,” Tate said.
This opens up a whole swath of new options. “If it runs faster on the Xilinx boards than on an Intel Xeon, and the price is better, the customer just wants throughput per dollar and the FPGA can do better,” said Tate. “In the Microsoft data center, they run their inference on FPGAs because the FPGA needs a lot of multiplier-accumulators and the Xeons don’t have them. Microsoft has shown for years that FPGA is good for inference.”
Flex Logix’s path to an inference chip started with a customer asking for an FPGA that was optimized for inferencing. “There was a time when FPGAs just had logic,” he said. “There were no multiplier-accumulators in them. That was in the ’80s, when Xilinx first came out with them. At a later point in time, all FPGAs had multiplier-accumulators in them, introduced primarily for signal processing. They were optimized in terms of their size and their function for signal processing applications. Those multiplier-accumulators are why Microsoft is doing inference using FPGAs, because FPGAs have a fair number of multiplier-accumulators,” Tate explained.
Then development teams started using GPUs for inferencing, because they also have a lot of multipliers and accumulators. But they weren’t optimized for inference, although Nvidia has been slowly optimizing that. Flex Logix’s customer asked the company to change its FPGA in two ways — change all the MACs from 22-bit to 8-bit, and throw away all the extra bits and make a smaller multiplier-accumulator. The second request, given that the MAC was smaller and more could be fit into the same area, was to allocate more area to MACs.
“We’ll find out over this next year which of the architectures actually deliver better throughput per dollar, or the throughput per watt, and those will be the winners,” Tate said. “The customer doesn’t care which one wins. To them it’s just a piece of silicon. They put in their neural model, the software does the magic to make the silicon work, and they don’t care what’s inside as long as the answers come out, at high throughput, and the price and power are right.”
Looks like they decided on which way to go and it involved Xilinx and it that’s the case it could point towards “Explosive growth“.
A previous post about Leddartech (involved with Mercedes) indicated a supplier of theirs was Renasas and their FPGA supplier was Xilinx. How good is that for a link?
Good times ahead!
Attachments
Last edited:
Bravo
Meow Meow 🐾
Thank goodness you're here. Welcome you fantastic foot model, researcher extraordinaire and DJ of the eclectic groove.
View attachment 377
OMG! Thanks so much Hoppy! Wow, it's so nice of you to think of me! But the foot (above) is seriously uggsie. Never mind, I know I need to practice more humility. I shouldn't let it get to my head too much that my feet look so good, because it literally had nothing to do with me. I think I need to thank my father.Thank goodness you're here. Welcome you fantastic foot model, researcher extraordinaire and DJ of the eclectic groove.
View attachment 377
Fact Finder
Top 20
I agree with your recollection that AKIDA was simulated first on an FPGA and that Xilinx was the brand involved.Hi SG
From memory the development and early emulation of Akida before transitioning from software to silicon was on an FPGA (field programmable gate array) platform.
And the FPGA boards used were from Xilinx. FPGA's was Xilinx's speciality.
I believe BRN provided copies of these FPGA boards to Mercedes for their research, testing and benchmarking of Akida.
These dots between BRN and XILINX do exist.
One would hope that Xilinx would view the incorporation of Akida's IP into it's FPGA boards, much the same way Socionext is incorporating Akida into it's SynQuacer SC2A11 (I think) hardware.
Cheers
Cyber
My opinion only DYOR
FF
AKIDA BALLISTA
Dr E Brown
Regular
Hi everybody I was doing some research and came across this https://www.synaptics.com/technology/edge-computing
There seems to be a lot of crossover with Brainchip.
Are they using Akida or are they a competitor. Can any of our more intelligent members help out please.
Should add that they are working with Eta Compute who list Edge Impulse as a partner!
Thanks
There seems to be a lot of crossover with Brainchip.
Are they using Akida or are they a competitor. Can any of our more intelligent members help out please.
Should add that they are working with Eta Compute who list Edge Impulse as a partner!
Thanks
Infinity
Emerged
Great that everything went well the other day. We thank u heaps for mentoring me and assisting this arvo in moving here. Of course, am so grateful to all the generous and highly intelligent posters here. I learned so much.Hi folks. Just got myself set up. Missed a lot of the action as I was in hospital having a couple of hernias seen to. Just back this afternoon.
Seems all is well in a new and better environment. Some good action on Friday while I was under the knife!
Cheers, Deena
Muchas gracias!
Falling Knife
Regular
I think the Mods were so focused on the BRN forum they let one slip through to the keeper ROFL.
View attachment 401
Another BRN top rated post lol
That makes it look like they are winning and there is a mass exodus from BRN the stock.. lol
Monday tomorrow and we are not going to discuss cold crapper.... Rise above and move on I hope we do.
Feels like a good day for a rocket.
Dr E Brown
Regular
Don’t know if this has ever been linked before. Apologies if it has.
Samsung launched the first artificial intelligence security camera which can make on-device inference without sending data to servers, thus consuming lesser energy and maintains privacy (Figure 19) (Samsung, 2020).
Figure 19. Samsung SmartThings Vision is available in Australia (Samsung, 2020)
Samsung launched the first artificial intelligence security camera which can make on-device inference without sending data to servers, thus consuming lesser energy and maintains privacy (Figure 19) (Samsung, 2020).
Figure 19. Samsung SmartThings Vision is available in Australia (Samsung, 2020)
Dirac
Member
Aldehyde .... I think I knew her.Alcohol is broken down to aldehyde which causes headaches and nausea.
Rodney
Regular
Yes didn’t think of it that way when I wrote but think the forum understood. Not that it matters there is no one leftView attachment 417
That makes it look like they are winning and there is a mass exodus from BRN the stock.. lol
Monday tomorrow and we are not going to discuss cold crapper.... Rise above and move on I hope we do.
Feels like a good day for a rocket.
stockduck
Regular
Great for my understanding, so power, memory and bandwidth is also critical for every smartphone...right?I was on the Brainchip website and found where they were discussing Xilinx and have included an excerpt:
It’s under ”The challenge of building inferencing chips”. https://brainchipinc.com/challenges-of-inferencing-chips/
Speed matters
The key factor here is throughput. “These are generally plugged-in devices. Power is always critical, and there is only so much dissipation you can afford. But in the hierarchy of systems, there are other things that come before power. Memory is certainly another big component of AI inference at the edge. How much memory and how much bandwidth you can sustain?”
For companies building these chips, market opportunities are flourishing. Geoff Tate, CEO of Flex Logix, points to such markets as biomedical imaging for implementing AI in ultrasound systems, genomic systems, along with scientific imaging applications that require very high resolution and very high frame rate. Surveillance cameras for retail stores also are growing in use so retailers can extend the use of the cameras wired already into their servers to capture information such as how many customers are coming into the store, customer wait times, etc.
While many, if not most, inferencing chips are mainly CPU-based, Flex Logix uses some embedded FPGA technology in its inferencing chip. “Companies like Microsoft use FPGAs in their datacenter today. They’ve deployed FPGAs for some time. They’ve done it because they found workloads that are common in their datacenter for which they can write code that runs on the FPGA, and basically it will run faster at lower cost and power than if it ran on a processor,” Tate said.
This opens up a whole swath of new options. “If it runs faster on the Xilinx boards than on an Intel Xeon, and the price is better, the customer just wants throughput per dollar and the FPGA can do better,” said Tate. “In the Microsoft data center, they run their inference on FPGAs because the FPGA needs a lot of multiplier-accumulators and the Xeons don’t have them. Microsoft has shown for years that FPGA is good for inference.”
Flex Logix’s path to an inference chip started with a customer asking for an FPGA that was optimized for inferencing. “There was a time when FPGAs just had logic,” he said. “There were no multiplier-accumulators in them. That was in the ’80s, when Xilinx first came out with them. At a later point in time, all FPGAs had multiplier-accumulators in them, introduced primarily for signal processing. They were optimized in terms of their size and their function for signal processing applications. Those multiplier-accumulators are why Microsoft is doing inference using FPGAs, because FPGAs have a fair number of multiplier-accumulators,” Tate explained.
Then development teams started using GPUs for inferencing, because they also have a lot of multipliers and accumulators. But they weren’t optimized for inference, although Nvidia has been slowly optimizing that. Flex Logix’s customer asked the company to change its FPGA in two ways — change all the MACs from 22-bit to 8-bit, and throw away all the extra bits and make a smaller multiplier-accumulator. The second request, given that the MAC was smaller and more could be fit into the same area, was to allocate more area to MACs.
“We’ll find out over this next year which of the architectures actually deliver better throughput per dollar, or the throughput per watt, and those will be the winners,” Tate said. “The customer doesn’t care which one wins. To them it’s just a piece of silicon. They put in their neural model, the software does the magic to make the silicon work, and they don’t care what’s inside as long as the answers come out, at high throughput, and the price and power are right.”
Looks like they decided on which way to go and it involved Xilinx and it that’s the case it could point towards “Explosive growth“.
A previous post about Leddartech (involved with Mercedes) indicated a supplier of theirs was Renasas and their FPGA supplier was Xilinx. How good is that for a link?
Good times ahead!
I hold 10 stocks, half of them bought before BRN. Started buying BRN from 17 cents, my only substantial green stock is BRN. I wish I had all my money on BRN, but you always have a choice, hope you make a right oneToo late to buy in at this price ? Stupid question I know as those who love the company expect it to go much higher. Just trying to assess risk, as the saying goes don't invest what you can't afford to lose and diversify.
View attachment 254
YLJ
Swing/Position Trader
Thank you @Rayz for your generous input. As I read this gem of an article again, I remembered that I had seen it before a long time ago.This explains in simple terms just how effective Akida is
https://www.eetindia.co.in/keyword-spotting-making-an-on-device-assistant-a-reality/
Article By : Peter AJ van der Made, BrainChip
Natural-language processing technique known as keyword spotting is gaining traction with the proliferation of smart appliances controlled by voice commands.
Voice assistants from Amazon, Google, Apple and others can respond to a phrase that follows a “hot word” such as “Hey, Google” or “Hey, Siri” and appear to respond almost immediately. In fact, the response has a delay of a fraction of a second, which is acceptable in a smart speaker device.
How can a small device be so clever?
The voice assistant uses a digital signal processor to digest the first “hot word.” The phrases that follow are sent via the Internet to the cloud.
The speech is then converted into streams of numbers, which are processed in a recurrent convolutional neural network that remembers previous internal states, so that it can be trained to recognize phrases or sequences of words.
These data streams are processed in a datacenter, and the answer or song requested is sent back to the voice assistant via the web. This works well in situations that are non-critical, where a delay does not matter and where Internet connections are reliable.
The neural networks located in data centers are trained using millions of samples in a method that resembles successive approximation; errors are initially very large, but are reduced by feeding the error back into an algorithm that adjusts the network parameters.
The error is reduced in each training cycle.
Training cycles are then repeated until the output is correct.
This is done for every word and phrase in the dataset. Training such networks can take a very long time, on the order of weeks.
Once trained, the network can recognize words and phrases spoken by different individuals.
The recognition process, called inference, is computed and requires millions of multiplications followed by accumulate (MAC) operations, which is why the information cannot be processed in a timely manner on a microprocessor within the device.
In keyword spotting, multiple words need to be recognized.
The delay of sending it to the datacenter is not acceptable, and Internet connections are not always guaranteed. Hence, local processing of phrases on the device is preferable.
One solution is to shrink the multiply-accumulate functions into smaller chips.
The Google Edge-Tensor Processing Unit (TPU), for instance, incorporates many array multipliers and math functions.
This solution still requires a microprocessor to run the neural network, but the MAC functions are passed on to the chip and accelerated.
While this approach allows a small microprocessor to run larger neural networks, it comes with disadvantages:
The power consumption remains too high for small or battery-powered appliances.
With diminishing size comes diminishing performance.
Small dedicated arrays of multipliers are not as plentiful or as fast as those provided by large, power-hungry GPUs or TPUs in datacenters.
An alternative approach involves smaller, tighter neural networks for keyword processing.
Rather than performing complex processing techniques in large recurrent networks, these networks process keywords by converting a stream of values into a spectrograph using a voice recognition algorithm known as MFCC.
The spectrograph picture is input to a much simpler 7-layer feed-forward neural network that has been trained to recognize the features of a keyword set.
The Google keyword dataset, for instance, consists of 65,000 one-second samples of 30 individual words spoken by thousands of different people.
Examples of keywords are UP, DOWN, LEFT, RIGHT, STOP, GO, ON and OFF.
An alternative approach
We have taken a completely different approach, processing sound, images, data and odors in event-based hardware. Brainchip was founded long before the current machine learning rage.
The advancement of processing methods for neural networks and artificial intelligence are our main aims, and we are focused on neuromorphic hardware designs.
The human brain does not run instructions, but instead relies on neural cells.
These cells process information and communicate in spikes, which are short bursts of electrical energy which express the occurrence of an “event” such as a change in color, a line, a frequency, or touch.
By contrast, computers are designed to operate on data bits and execute instructions written by a programmer.
These are two very different processing techniques.
It takes many computer instructions to emulate the function of brain cells — in the form of a neural network — on a computer.
We realized we could do away with the instructions and build very efficient digital circuits that compute in the same way the brain does.
The brain is the ultimate example of a general intelligent system.
This is exactly what Brainchip has done to develop the Akida neural processor.
The chip evolved further when we combined deep learning capabilities with the event-based spiking neural network (SNN) hardware, thus significantly lowering power requirements and improving performance — with the added advantage of rapid on-chip learning.
The Akida chip can process the Google keyword dataset, utilizing the simple 7-layer neural network described above, within a power budget of less than 200 microwatts.
Akida was trained using the the ImageNet dataset, enabling it to instantly learn to recognize a new object without expensive retraining.
The chip has built-in sparsity.
The all-digital design is event-based and therefore does not produce any output when the input stimulus does not cause the neuron to exceed the threshold.
This can be illustrated in a simplified, although extreme example.
Imagine an image with a single dot in the middle.
A conventional neural network needs to process every location of the image to determine if there is something there.
It takes a block of pixels from the image and performs a convolution.
The results are zero, and these zeros are propagated throughout the entire network, together with the zeros generated by all the other blocks, until it reaches the dot.
To detect and eliminate the zeros would add additional latency and would cause processing to slow down rather than speed it up.
Nearly 500 million operations are required to determine that there is a single dot in the image.
By contrast, the Akida event-based approach responds only to the one event, the single dot.
All other locations contain no information and zeros are not propagated through the network, because they do not generate an event.
In practical terms, with real images this sparsity results in up to 40 to 60 percent fewer computations to produce the same classification results using less power.
Training Akida
A keyword spotting application using the Akida chip trained on the Google Speech Commands Dataset can run for years off a penlight battery.
The same circuit configured to use 30 layers and all 80 neural processing units on the chip can be used to process the entire ImageNet dataset in real-time at less than 200 milliwatts (about five days on a penlight battery).
The MobileNet network for image classification fits comfortably on the chip, including all the required memory.
The on-chip, real-time learning capability makes it possible to add to the library of learned words, a nice feature that can be used for personalized word recognition like names, places and customized commands.
Another option for keyword spotting is the Syntiant NDP101 chip.
While this device also operates at comparable low power (200 microwatts) it is a dedicated audio processor that integrates an audio front end, buffering and feature extraction together with the neural network. Syntiant expects to replace digital MACs with an in-memory analog circuit in the future to further reduce power.
The Akida chip has the added advantages of on-chip learning and versatility. It can also be reconfigured to perform sound or image classification, odor identification or to classify features extracted from data. Another advantage of local processing is that no images or data are exposed on the Internet, significantly reducing privacy risks.
Applications for the technology range from voice-activated appliances to replacing worn-out components in manufacturing equipment.
The technology also could be used to determine tire wear based on the sound a tire makes on a road surface.
Other automotive applications include monitoring a driver’s alertness, listening to the engine to determine if maintenance is required and scanning for vehicles in the driver’s blind spot.
We expect Akida to evolve, incorporating the structures of the brain, particularly cortical neural networks aimed at artificial general intelligence (AGI).
This is a form of machine intelligence that can be trained to perform multiple tasks.
AGI technology can be used for controlling autonomous vehicles, with sufficient intelligence to control a vehicle and eventually learn to drive much like humans learn.
To be sure, there will be many intermediate steps along the way to that goal.
A future Akida device will include a more sophisticated neural network model that can lean increasingly complex tasks. Stay tuned.
— Peter AJ van der Made is the CTO of Brainchip.
For those who have not noticed, there is a great feature to this forum that can save a lot of time if you are the type to save research
you come across for future reference... there is a bookmark option at the top right of every post...
thelittleshort
Top Bloke
Not sure if these have been posted already
I found these Semiconductor Engineering website articles from the last few days very interesting and relevant to the automotive industry and Akida - well worth a read
The site mentions Brainchip in several other articles on their website
Automotive Outlook: 2022
ML Focus Shifting Toward Software
Cheers
TLS
This on Twitter today - USA vs China in chip production race
House passes bill that would put billions toward US chip production The America COMPETES
Act of 2022 seeks to position the US on equal footing with China.
On Friday, the US House of Representatives passed the America COMPETES Act of 2022 almost entirely along party lines. Among other measures, the sprawling 2,900-page bill allocates $52 billion in grants to subsidize semiconductor manufacturing. It also authorizes nearly $300 billion for research and development.
If enacted, the legislation would represent the most comprehensive attempt by the US to match China’s recent technological and industrial dominance. However, as The New York Times points out, it is unlikely to pass in its current iteration. Much of that comes down to ideological differences between how Democrats and Republicans think the federal government can best position the country to compete against China.
Similar threads
- Replies
- 3
- Views
- 12K
D
- Replies
- 0
- Views
- 5K
- Replies
- 9
- Views
- 6K
- Replies
- 0
- Views
- 3K