You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
BRN Discussion Ongoing
- Thread starter TechGirl
- Start date
Sirod69
bavarian girl ;-)
Klinische Studien zur COVID-19: DiaNose - Register für klinische Studien - ICH GCP
Ziel der Studie ist es, Daten potenzieller flüchtiger organischer Verbindungen (VOCs) zu sammeln und zu analysieren. die zur Unterscheidung zwischen Patienten mit und ohne COVID-19 oder mit Hochrisiko für COVID-19 durch DiaNose-Atemtest. Bis zu 300 Probanden werden in die Studie aufgenommen (...
 ichgcp.net
ichgcp.net
D
Deleted member 118
Guest
Edge focus areas | Royal Australian Air Force
Edge focus areasFour key lines of effort have been identified to realise the Air Force’s augmented intelligence ambition. These lines of effort focus on exploring the edges of a fifth-generation Force to create, accelerate, and exploit opportunities for advantage. Autonomous processingThe Air...
Fact Finder
Top 20
This NaNose study involved testing 10,000 people. By May 2021 they had tested about 7,000 and the study was extended for 12 months to test the remaining 3,000. When the testing is complete then they have to compile the results and report them to the FDA then wait for the FDA to advise what they decide. Still a lot of work to do.does somebody knows what´s with this covid 19 test study, i think it isn´t still ready or was there something wrong, didn´t it work???Klinische Studien zur COVID-19: DiaNose - Register für klinische Studien - ICH GCP
Ziel der Studie ist es, Daten potenzieller flüchtiger organischer Verbindungen (VOCs) zu sammeln und zu analysieren. die zur Unterscheidung zwischen Patienten mit und ohne COVID-19 oder mit Hochrisiko für COVID-19 durch DiaNose-Atemtest. Bis zu 300 Probanden werden in die Studie aufgenommen (...
My opinion only DYOR
FF
AKIDA BALLISTA
Fact Finder
Top 20
Edge focus areas | Royal Australian Air Force
Edge focus areasFour key lines of effort have been identified to realise the Air Force’s augmented intelligence ambition. These lines of effort focus on exploring the edges of a fifth-generation Force to create, accelerate, and exploit opportunities for advantage. Autonomous processingThe Air...www.airforce.gov.au
View attachment 4375
D
Deleted member 118
Guest
Fact Finder
Top 20


D
Deleted member 118
Guest
LolAt least.
D
Deleted member 118
Guest
From our friends over at the Asylum

Last edited by a moderator:
Fact Finder
Top 20
That was very nice of the group at HC. I thought they didn’t care.
Fact Finder
Top 20
- Home
- Innovation and Technologies
- Technologies
- Interior cocoon
INTERIOR COCOON: ONBOARD TECHNOLOGIES FOR IMPROVED PASSENGER SAFETY
- a driver monitoring system, which uses a camera to analyze the driver’s face using artificial intelligence (AI) algorithms,
- a cabin monitoring system to detect occupant behavior, and
- the life detection system, which signals if a child or animal is in the rear of the locked vehicle.
WHAT IS A DRIVER MONITORING SYSTEM?
A driver-monitoring system is an advanced safety technology that uses a camera to monitor driver alertness and check their level of vigilance. It is an innovative concept for active safety that can help reduce accidents on the road.Valeo’s Driver Monitoring System has many functions such as detection of distraction and drowsiness, driver identification and facial emotion recognition.
When it detects signs of sleepiness or distraction, the system transmits alerts to the driver to get the driver’s attention back on the task of driving. The system’s camera mounted on the dashboard also ensures that the driver has their eyes on the road.

Other applications are also possible, such as driver identification for personalized settings and adapted driving modes.
Valeo’s Driver Monitoring System is in mass production with Deep Learning algorithms, including a scalable ECU and cameras for driver identification, accurate head-and-eye tracking, and monitoring driver gaze for distraction or drowsiness.
The driver monitoring system will contribute 25% of the ADAS evaluation and occupant condition monitoring to EuroNCap. The improvement of this automotive safety technology will contribute to the reduction of accidents related to fatigue and distraction, which account for 54% of fatal accidents in Europe. Camera-based driver identification also provides an additional level of security compared to key or badge-based access systems.

Since the DMS is becoming mandatory for L2 and L2+ autonomous vehicles, the global market is exploding, from about 1 million units in 2020 to an estimated 22 million units in 2025.
INNOVATIVE AUTOMOTIVE MONITORING SYSTEM FOR PASSENGER SAFETY
WHAT IS A CABIN MONITORING SYSTEM?
A cabin-monitoring system uses a camera sensor to understand human behavior and detect any passenger movements.Thanks to the Valeo Interior Monitoring System, the vehicle is able to adapt to the internal context by knowing the characteristics of occupants such as their posture, and then adapting elements such as the air temperature or the driving mode. In addition, in the event of an accident, the intensity and deployment timing of the airbags can be adjusted according to the position and size of each passenger.

The cabin monitoring system, which is equipped with a camera, also allows entertainment functions such as taking selfies to share experiences while traveling.

Valeo Gesture recognitionoffers a natural and intuitive way to interact with the vehicle for even safer driving. Based on machine-learning algorithms and an in-house compact 3D camera, the feature is embedded in Valeo’s dome module.

A RADAR TO DETECT PRESENCE OF PASSENGERS IN THE VEHICLE
The Life Presence Detection System uses interior radar and AI algorithms to detect if there’s life or not in the car. Result: no more children or pets forgotten in the back of the car anymore thanks to this additional safety technology. Once the engine is turned off and the car is locked, if the car detects that a person or a pet is still inside the vehicle, the system activates an audible and visual alarm on a smartphone.Valeo’s “Life Presence Detection” solution is based on a 60 GHz radar using a millimeter wave detection system to detect in real-time occupants’ body movements, as subtle as breathing-related chest movements, even under visual obstacles such as clothing, blankets, etc.

Such systems with passenger movement detection are usually integrated in the vehicle roof liner and must be able to detect or assess the presence of a child or a pet in a locked vehicle and either provide warnings for as long as necessary or intervene to mitigate the risk of hyperthermia.
In Europe, EuroNcap has included life detection in its roadmap to address the problem of children left unattended in a vehicle, which leads to heatstroke injury and death.
Since 2022, this in-car monitoring feature is considered a key safety criterion in EuroNcap’s evaluation
F
Filobeddo
Guest
Second that @robsmark , I wasn’t initially sold as well on Sean but early signs are very promising, articulate, intelligent, polished, passionate and driven. But still needs to get a decent haircutI wasn’t completely sold on Sean, but after watching the latest podcast, he seems to have a firm grasp on the companies background, position, and potential future. I stand by my earlier comments about early hyping 2022 (I understand this wasn’t Sean), but I also understand that there’s still another eight months to come up with some revenue, and or commercial customers.
I‘ve cooled off after my tantrum yesterdayand remain confident of the future of this company. I picked up a couple of thousand shares today, and have transferred a larger sum to my trading account to pick up another parcel tomorrow.
GLTAH.
Last edited by a moderator:
F
Filobeddo
Guest
@dippY22 , think Sean mentioned in the strawman pres that they are pressing customers if they can announceWith respect to the angst associated with NDA's discussed previously, I would just like to opine that I still believe that Brainchip may in fact be asking for these as well as some or all of the early adopters.
It is in Brainchip's immense interest to not have others say anything negative, or express missgivings about Akida's tech once that early adopter status ceases, or perhaps is not proceeding in a way both parties had hoped or anticipated.
If I had the inside line to corporate that some of you have I would ask them if Brainchip asks for NDA's. What could they possibly say? Yes, no, or we can't address that....Any of these responses would be acceptable to me because a yes response needs no explanation, a no response would be very revealing, and the ambiguous, "we can't address that" would also be pretty clear to me that they are.
But bottom line,....would knowing somehow affect my investment if Brainchip were in fact asking for NDA's.......? Nope, it wouldn't.
Regards, dippY
F
Filobeddo
Guest
@Csharmo think you’ve found Yoda!!I'm happy to see this employee has over 135 years experience aswell!! Unbelievable!
Fact Finder
Top 20
When I read articles like this and consider how once upon a time in a world not that far away parents, grandparents, friends and strangers had the ability to remember for more than ten seconds that they had the care of a child and they were in the car with them and now Governments around the world are legislating to make car manufacturers include intelligent devices to supplement humans after their ten second memory span has been exhausted ALL I CAN SAY IS AS BLIND FREDDIE SAYS -
- Home
- Innovation and Technologies
- Technologies
- Interior cocoon
INTERIOR COCOON: ONBOARD TECHNOLOGIES FOR IMPROVED PASSENGER SAFETY
Valeo’s cocoon interior brings together several onboard technologies for improved passenger safety in the vehicle:
- a driver monitoring system, which uses a camera to analyze the driver’s face using artificial intelligence (AI) algorithms,
- a cabin monitoring system to detect occupant behavior, and
- the life detection system, which signals if a child or animal is in the rear of the locked vehicle.
WHAT IS A DRIVER MONITORING SYSTEM?
A driver-monitoring system is an advanced safety technology that uses a camera to monitor driver alertness and check their level of vigilance. It is an innovative concept for active safety that can help reduce accidents on the road.
Valeo’s Driver Monitoring System has many functions such as detection of distraction and drowsiness, driver identification and facial emotion recognition.
When it detects signs of sleepiness or distraction, the system transmits alerts to the driver to get the driver’s attention back on the task of driving. The system’s camera mounted on the dashboard also ensures that the driver has their eyes on the road.
Other applications are also possible, such as driver identification for personalized settings and adapted driving modes.
Valeo’s Driver Monitoring System is in mass production with Deep Learning algorithms, including a scalable ECU and cameras for driver identification, accurate head-and-eye tracking, and monitoring driver gaze for distraction or drowsiness.
The driver monitoring system will contribute 25% of the ADAS evaluation and occupant condition monitoring to EuroNCap. The improvement of this automotive safety technology will contribute to the reduction of accidents related to fatigue and distraction, which account for 54% of fatal accidents in Europe. Camera-based driver identification also provides an additional level of security compared to key or badge-based access systems.
Since the DMS is becoming mandatory for L2 and L2+ autonomous vehicles, the global market is exploding, from about 1 million units in 2020 to an estimated 22 million units in 2025.
INNOVATIVE AUTOMOTIVE MONITORING SYSTEM FOR PASSENGER SAFETY
WHAT IS A CABIN MONITORING SYSTEM?
A cabin-monitoring system uses a camera sensor to understand human behavior and detect any passenger movements.
Thanks to the Valeo Interior Monitoring System, the vehicle is able to adapt to the internal context by knowing the characteristics of occupants such as their posture, and then adapting elements such as the air temperature or the driving mode. In addition, in the event of an accident, the intensity and deployment timing of the airbags can be adjusted according to the position and size of each passenger.
The cabin monitoring system, which is equipped with a camera, also allows entertainment functions such as taking selfies to share experiences while traveling.
Valeo Gesture recognitionoffers a natural and intuitive way to interact with the vehicle for even safer driving. Based on machine-learning algorithms and an in-house compact 3D camera, the feature is embedded in Valeo’s dome module.
A RADAR TO DETECT PRESENCE OF PASSENGERS IN THE VEHICLE
The Life Presence Detection System uses interior radar and AI algorithms to detect if there’s life or not in the car. Result: no more children or pets forgotten in the back of the car anymore thanks to this additional safety technology. Once the engine is turned off and the car is locked, if the car detects that a person or a pet is still inside the vehicle, the system activates an audible and visual alarm on a smartphone.
Valeo’s “Life Presence Detection” solution is based on a 60 GHz radar using a millimeter wave detection system to detect in real-time occupants’ body movements, as subtle as breathing-related chest movements, even under visual obstacles such as clothing, blankets, etc.
Such systems with passenger movement detection are usually integrated in the vehicle roof liner and must be able to detect or assess the presence of a child or a pet in a locked vehicle and either provide warnings for as long as necessary or intervene to mitigate the risk of hyperthermia.
In Europe, EuroNcap has included life detection in its roadmap to address the problem of children left unattended in a vehicle, which leads to heatstroke injury and death.
Since 2022, this in-car monitoring feature is considered a key safety criterion in EuroNcap’s evaluation
‘This market that AKIDA technology can service is growing like a house on fire and will be worth a zillion billion dollar bucks.
The only way Brainchip will not capture at least one percent of this market is if they get high on cocaine and stay in bed for the next three years.
They truly are disrupting markets that do not exist yet and which are still to be thought of or imposed by Governments.’
My opinion only DYOR
FF
AKIDA BALLISTA
Build-it
Regular
does somebody knows what´s with this covid 19 test study, i think it isn´t still ready or was there something wrong, didn´t it work???Klinische Studien zur COVID-19: DiaNose - Register für klinische Studien - ICH GCP
Ziel der Studie ist es, Daten potenzieller flüchtiger organischer Verbindungen (VOCs) zu sammeln und zu analysieren. die zur Unterscheidung zwischen Patienten mit und ohne COVID-19 oder mit Hochrisiko für COVID-19 durch DiaNose-Atemtest. Bis zu 300 Probanden werden in die Studie aufgenommen (...
QUOTE="Fact Finder, post: 48168, member: 31"]
This NaNose study involved testing 10,000 people. By May 2021 they had tested about 7,000 and the study was extended for 12 months to test the remaining 3,000. When the testing is complete then they have to compile the results and report them to the FDA then wait for the FDA to advise what they decide. Still a lot of work to do.
My opinion only DYOR
FF
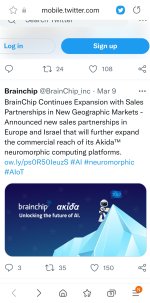
Where still in Israel & the expansion continues
Edge Compute.
Attachments
robsmark
Regular
Surly this has to be us?
- Home
- Innovation and Technologies
- Technologies
- Interior cocoon
INTERIOR COCOON: ONBOARD TECHNOLOGIES FOR IMPROVED PASSENGER SAFETY
Valeo’s cocoon interior brings together several onboard technologies for improved passenger safety in the vehicle:
- a driver monitoring system, which uses a camera to analyze the driver’s face using artificial intelligence (AI) algorithms,
- a cabin monitoring system to detect occupant behavior, and
- the life detection system, which signals if a child or animal is in the rear of the locked vehicle.
WHAT IS A DRIVER MONITORING SYSTEM?
A driver-monitoring system is an advanced safety technology that uses a camera to monitor driver alertness and check their level of vigilance. It is an innovative concept for active safety that can help reduce accidents on the road.
Valeo’s Driver Monitoring System has many functions such as detection of distraction and drowsiness, driver identification and facial emotion recognition.
When it detects signs of sleepiness or distraction, the system transmits alerts to the driver to get the driver’s attention back on the task of driving. The system’s camera mounted on the dashboard also ensures that the driver has their eyes on the road.
Other applications are also possible, such as driver identification for personalized settings and adapted driving modes.
Valeo’s Driver Monitoring System is in mass production with Deep Learning algorithms, including a scalable ECU and cameras for driver identification, accurate head-and-eye tracking, and monitoring driver gaze for distraction or drowsiness.
The driver monitoring system will contribute 25% of the ADAS evaluation and occupant condition monitoring to EuroNCap. The improvement of this automotive safety technology will contribute to the reduction of accidents related to fatigue and distraction, which account for 54% of fatal accidents in Europe. Camera-based driver identification also provides an additional level of security compared to key or badge-based access systems.
Since the DMS is becoming mandatory for L2 and L2+ autonomous vehicles, the global market is exploding, from about 1 million units in 2020 to an estimated 22 million units in 2025.
INNOVATIVE AUTOMOTIVE MONITORING SYSTEM FOR PASSENGER SAFETY
WHAT IS A CABIN MONITORING SYSTEM?
A cabin-monitoring system uses a camera sensor to understand human behavior and detect any passenger movements.
Thanks to the Valeo Interior Monitoring System, the vehicle is able to adapt to the internal context by knowing the characteristics of occupants such as their posture, and then adapting elements such as the air temperature or the driving mode. In addition, in the event of an accident, the intensity and deployment timing of the airbags can be adjusted according to the position and size of each passenger.
The cabin monitoring system, which is equipped with a camera, also allows entertainment functions such as taking selfies to share experiences while traveling.
Valeo Gesture recognitionoffers a natural and intuitive way to interact with the vehicle for even safer driving. Based on machine-learning algorithms and an in-house compact 3D camera, the feature is embedded in Valeo’s dome module.
A RADAR TO DETECT PRESENCE OF PASSENGERS IN THE VEHICLE
The Life Presence Detection System uses interior radar and AI algorithms to detect if there’s life or not in the car. Result: no more children or pets forgotten in the back of the car anymore thanks to this additional safety technology. Once the engine is turned off and the car is locked, if the car detects that a person or a pet is still inside the vehicle, the system activates an audible and visual alarm on a smartphone.
Valeo’s “Life Presence Detection” solution is based on a 60 GHz radar using a millimeter wave detection system to detect in real-time occupants’ body movements, as subtle as breathing-related chest movements, even under visual obstacles such as clothing, blankets, etc.
Such systems with passenger movement detection are usually integrated in the vehicle roof liner and must be able to detect or assess the presence of a child or a pet in a locked vehicle and either provide warnings for as long as necessary or intervene to mitigate the risk of hyperthermia.
In Europe, EuroNcap has included life detection in its roadmap to address the problem of children left unattended in a vehicle, which leads to heatstroke injury and death.
Since 2022, this in-car monitoring feature is considered a key safety criterion in EuroNcap’s evaluation
Kachoo
Regular
You make me laugh hard at time FF lolWhen I read articles like this and consider how once upon a time in a world not that far away parents, grandparents, friends and strangers had the ability to remember for more than ten seconds that they had the care of a child and they were in the car with them and now Governments around the world are legislating to make car manufacturers include intelligent devices to supplement humans after their ten second memory span has been exhausted ALL I CAN SAY IS AS BLIND FREDDIE SAYS -
‘This market that AKIDA technology can service is growing like a house on fire and will be worth a zillion billion dollar bucks.
The only way Brainchip will not capture at least one percent of this market is if they get high on cocaine and stay in bed for the next three years.
They truly are disrupting markets that do not exist yet and which are still to be thought of or imposed by Governments.’
My opinion only DYOR
FF
AKIDA BALLISTA
Fact Finder
Top 20
I just have to say it.
- Home
- Innovation and Technologies
- Technologies
- Interior cocoon
INTERIOR COCOON: ONBOARD TECHNOLOGIES FOR IMPROVED PASSENGER SAFETY
Valeo’s cocoon interior brings together several onboard technologies for improved passenger safety in the vehicle:
- a driver monitoring system, which uses a camera to analyze the driver’s face using artificial intelligence (AI) algorithms,
- a cabin monitoring system to detect occupant behavior, and
- the life detection system, which signals if a child or animal is in the rear of the locked vehicle.
WHAT IS A DRIVER MONITORING SYSTEM?
A driver-monitoring system is an advanced safety technology that uses a camera to monitor driver alertness and check their level of vigilance. It is an innovative concept for active safety that can help reduce accidents on the road.
Valeo’s Driver Monitoring System has many functions such as detection of distraction and drowsiness, driver identification and facial emotion recognition.
When it detects signs of sleepiness or distraction, the system transmits alerts to the driver to get the driver’s attention back on the task of driving. The system’s camera mounted on the dashboard also ensures that the driver has their eyes on the road.
Other applications are also possible, such as driver identification for personalized settings and adapted driving modes.
Valeo’s Driver Monitoring System is in mass production with Deep Learning algorithms, including a scalable ECU and cameras for driver identification, accurate head-and-eye tracking, and monitoring driver gaze for distraction or drowsiness.
The driver monitoring system will contribute 25% of the ADAS evaluation and occupant condition monitoring to EuroNCap. The improvement of this automotive safety technology will contribute to the reduction of accidents related to fatigue and distraction, which account for 54% of fatal accidents in Europe. Camera-based driver identification also provides an additional level of security compared to key or badge-based access systems.
Since the DMS is becoming mandatory for L2 and L2+ autonomous vehicles, the global market is exploding, from about 1 million units in 2020 to an estimated 22 million units in 2025.
INNOVATIVE AUTOMOTIVE MONITORING SYSTEM FOR PASSENGER SAFETY
WHAT IS A CABIN MONITORING SYSTEM?
A cabin-monitoring system uses a camera sensor to understand human behavior and detect any passenger movements.
Thanks to the Valeo Interior Monitoring System, the vehicle is able to adapt to the internal context by knowing the characteristics of occupants such as their posture, and then adapting elements such as the air temperature or the driving mode. In addition, in the event of an accident, the intensity and deployment timing of the airbags can be adjusted according to the position and size of each passenger.
The cabin monitoring system, which is equipped with a camera, also allows entertainment functions such as taking selfies to share experiences while traveling.
Valeo Gesture recognitionoffers a natural and intuitive way to interact with the vehicle for even safer driving. Based on machine-learning algorithms and an in-house compact 3D camera, the feature is embedded in Valeo’s dome module.
A RADAR TO DETECT PRESENCE OF PASSENGERS IN THE VEHICLE
The Life Presence Detection System uses interior radar and AI algorithms to detect if there’s life or not in the car. Result: no more children or pets forgotten in the back of the car anymore thanks to this additional safety technology. Once the engine is turned off and the car is locked, if the car detects that a person or a pet is still inside the vehicle, the system activates an audible and visual alarm on a smartphone.
Valeo’s “Life Presence Detection” solution is based on a 60 GHz radar using a millimeter wave detection system to detect in real-time occupants’ body movements, as subtle as breathing-related chest movements, even under visual obstacles such as clothing, blankets, etc.
Such systems with passenger movement detection are usually integrated in the vehicle roof liner and must be able to detect or assess the presence of a child or a pet in a locked vehicle and either provide warnings for as long as necessary or intervene to mitigate the risk of hyperthermia.
In Europe, EuroNcap has included life detection in its roadmap to address the problem of children left unattended in a vehicle, which leads to heatstroke injury and death.
Since 2022, this in-car monitoring feature is considered a key safety criterion in EuroNcap’s evaluation
I wonder whether when Peter van der Made was working on his dream of creating AGi selling his unit in Sydney to fund his work before entering onto the ASX to seek funding from visionary retail investors did he ever imagine he could achieve in cabin selfies.
Look mum we are in a car.
How badly do we need artificial intelligence.
No wonder Puto thought he could steam roll the West.
My opinion only DYOR
FF
AKIDA BALLISTA
Similar threads
- Replies
- 3
- Views
- 12K
D
- Replies
- 0
- Views
- 5K
- Replies
- 9
- Views
- 6K
- Replies
- 0
- Views
- 3K