Nice to see a paper presented to give some measurable comparison to others.
Obviously doesn't cover all competitors and I'm sure I read once before when formal MLPerf testing done it's not cheap...someone can correct that if not the case.
Anyway, I see certain players in the industry have been talking about lowering / creating a newer benchmark standard.
Recent article below with some relevant statements imo.
Maybe they need to lower it already as per the comment in the conclusion...though presume not many out there could meet it yet haha
Less precision equals lower power, but standards are required to make this work.

semiengineering.com
Will Floating Point 8 Solve AI/ML Overhead?
Less precision equals lower power, but standards are required to make this work.
JANUARY 12TH, 2023 - BY:
KAREN HEYMAN
While the media buzzes about the Turing Test-busting results of ChatGPT, engineers are focused on the hardware challenges of running large language models and other deep learning networks. High on the ML punch list is how to run models more efficiently using less power, especially in critical applications like self-driving vehicles where latency becomes a matter of life or death.
AI already has led to a rethinking of computer architectures, in which the conventional von Neumann structure is replaced by near-compute and at-memory floorplans. But novel layouts aren’t enough to achieve the power reductions and speed increases required for deep learning networks. The industry also is updating the standards for floating-point (FP) arithmetic.
“There is a great deal of research and study on new data types in AI, as it is an area of rapid innovation,” said David Bell, product marketing director, Tensilica IP at
Cadence. “Eight-bit floating-point (FP8) data types are being explored as a means to minimize hardware — both compute resources and memory — while preserving accuracy for network models as their complexities grow.”
As part of that effort, researchers at Arm, Intel, and Nvidia published a white paper proposing
“FP8 Formats for Deep Learning.” [1]
“Bit precision has been a very active topic of debate in machine learning for several years,” said Steve Roddy, chief marketing officer at
Quadric. “Six or eight years ago when models began to explode in size (parameter count), the sheer volume of shuffling weight data into and out of training compute (either CPU or GPU) became the performance limiting bottleneck in large training runs. Faced with a choice of ever more expensive memory interfaces, such as HBM, or cutting bit precision in training, a number of companies experimented successfully with lower-precision floats. Now that networks have continued to grow exponentially in size, the exploration of FP8 is the next logical step in reducing training bandwidth demands.”
How we got here
Floating-point arithmetic is a kind of scientific notation, which condenses the number of digits needed to represent a number. This trick is pulled off by an arithmetic expression first codified by IEEE working group 754 in 1986, when floating-point operations generally were performed on a co-processor.
IEEE 754 describes how the radix point (more commonly known in English as the “decimal” point) doesn’t have a fixed position, but rather “floats” where needed in the expression. It allows numbers with extremely long streams of digits (whether originally to the left or right of a fixed point) to fit into the limited bit-space of computers. It works in either base 10 or base 2, and it’s essential for computing, given that binary numbers extend to many more digits than decimal numbers (100 = 1100100).
Fig. 1: 12.345 as a base-10 floating-point number.
Source: Wikipedia
While this is both an elegant solution and the bane of computer science students worldwide, its terms are key to understanding how precision is achieved in AI. The statement has three parts:
- A sign bit, which determines whether the number is positive (0) or negative (1);
- An exponent, which determines the position of the radix point, and
- A mantissa, or significand, which represents the most significant digits of the number.
Fig. 2: IEEE 754 floating-point scheme. Source: WikiHow
As shown in figure 2, while the exponent gains 3 bits in a 64-bit representation, the mantissa jumps from 32 bits to 52 bits. Its length is key to precision.
IEEE 754, which defines FP32 bit and FP64, was designed for scientific computing, in which precision was the ultimate consideration. Currently,
IEEE working group P3109 is developing a new standard for machine learning, aligned with the current (2019) version of 754. P3109 aims to create a floating-point 8 standard.
Precision tradeoffs
Machine learning often needs less precision than a 32-bit scheme. The white paper proposes two different flavors of FP8: E4M3 (4-bit exponent and 3-bit mantissa) and E5M2 (5-bit exponent and 2-bit mantissa).
“Neural networks are a bit strange in that they are actually remarkably tolerant to relatively low precision,” said Richard Grisenthwaite, executive vice president and chief architect at
Arm. “In our paper, we showed you don’t need 32 bits of mantissa for precision. You can use only two or three bits, and four or five bits of exponent will give you sufficient dynamic range. You really don’t need the massive precision that was defined in 754, which was designed for finite element analysis and other highly precise arithmetic tasks.”
Consider a real-world example: A weather forecast needs the extreme ranges of 754, but a self-driving car doesn’t need the fine-grained recognition of image search. The salient point is not whether it’s a boy or girl in the middle of the road. It’s just that the vehicle must immediately stop, with no time to waste on calculating additional details. So it’s fine to use a floating point with a smaller exponent and much smaller mantissa, especially for edge devices, which need to optimize energy usage.
“Energy is a fundamental quantity and no one’s going to make it go away as an issue,” said Martin Snelgrove, CTO of Untether AI. “And it’s also not a narrow one. Worrying about energy means you can’t afford to be sloppy in your software or your arithmetic. If doing a 32-bit floating point makes everything easier, but massively more power consuming, you just can’t do it. Throwing an extra 1,000 layers at something makes it slightly more accurate, but the value for power isn’t there. There’s an overall discipline about energy — the physics says you’re going to pay attention to this, whether you like it or not.”
In fact, to save energy and performance overhead, many deep learning networks had already shifted to an IEEE-approved
16-bit floating point and other formats, including mantissa-less integers. [2]
“Because compute energy and storage is at a premium in devices, nearly all high-performance device/edge deployments of ML always have been in INT8,” Quadric’s Roddy said. “Nearly all NPUs and accelerators are INT-8 optimized. An FP32 multiply-accumulate calculation takes nearly 10X the energy of an INT8 MAC, so the rationale is obvious.”
Why FP8 is necessary
The problem starts with the basic design of a deep learning network. In the early days of AI, there were simple, one-layer models that only operated in a feedforward manner. In 1986, David Rumelart, Geoffrey Hinton, and Ronald Williams published a
breakthrough paper on back-propagation [3] that kicked off the modern era of AI. As their abstract describes, “The procedure repeatedly adjusts the weights of the connections in the network so as to minimize a measure of the difference between the actual output vector of the net and the desired output vector. As a result of the weight adjustments, internal ‘hidden’ units, which are not part of the input or output, come to represent important features of the task domain, and the regularities in the task are captured by the interactions of these units.”
In other words, they created a system in which better results could be achieved by adding more and more layers into a model, which would be improved by incorporating “learned” adjustments. Decades later, their ideas so vastly improved machine translation and transcription that college professors remain unsure whether undergraduates’ essays have been written by bots.
But additional layers require additional processing power. “Larger networks with more and more layers were found to be progressively more successful at neural networks tasks, but in certain applications this success came with an ultimately unmanageable increase in memory footprint, power consumption, and compute resources. It became imperative to reduce the size of the data elements (activations, weights, gradients) from 32 bits, and so the industry started using 16-bit formats, such as Bfloat16 and IEEE FP16,” according to the paper jointly written by Arm/Intel/Nvidia.
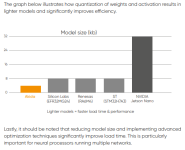
“The tradeoff fundamentally is with an 8-bit floating-point number compared to a 32-bit one,” said Grisenthwaite. “I can have four times the number of weights and activations in the same amount of memory, and I can get far more computational throughput as well. All of that means I can get much higher performance. I can make the models more involved. I can have more weights and activations at each of the layers. And that’s proved to be more useful than each of the individual points being hyper-accurate.”
Behind these issues are the two basic functions in machine learning, training and inference. Training is the first step in which, for example, the AI learns to classify features in an image by reviewing a dataset. With inference, the AI is given novel images outside of the training set and asked to classify them. If all goes as it should, the AI should distinguish that tails and wings are not human features, and at finer levels, that airplanes do not have feathers and a tube with a tail and wings is not a bird.
“If you’re doing training or inference, the math is identical,” said Ron Lowman, strategic marketing manager for IoT at
Synopsys. “The difference is you do training over a known data set thousands of times, maybe even millions of times, to train what the results will be. Once that’s done, then you take an unknown picture and it will tell you what it should be. From a math perspective, a hardware perspective, that’s the big difference. So when you do training, you want to do that in parallel, rather than doing it in a single hardware implementation, because the time it takes to do training is very costly. It could take weeks or months, or even years in some cases, and that just costs too much.”
In industry, training and inference have become separate specialties, each with its own dedicated teams.
“Most companies that are deploying AI have a team of data scientists that create neural network architectures and train the networks using their datasets,” said Bob Beachler, vice president of product at Untether AI. “Most of the autonomous vehicle companies have their own data sets, and they use that as a differentiating factor. They train using their data sets on these novel network architectures that they come up with, which they feel gives them better accuracy. Then that gets taken to a different team, which does the actual implementation in the car. That is the inference portion of it.”
Training requires a wide dynamic range for the continual adjustment of coefficients that is the hallmark of backpropagation. The inference phase is computing on the inputs, rather than learning, so it needs much less dynamic range. “Once you’ve trained the network, you’re not tweaking the coefficients, and the dynamic range required is dramatically reduced,” explained Beachler.
For inference, continuing operations in FP32 or FP16 is just unnecessary overhead, so there’s a quantization step to shift the network down to FP8 or Integer 8 (Int8), which has become something of a de facto standard for inference, driven largely by TensorFlow.
“The idea of quantization is you’re taking all the floating point 32 bits of your model and you’re essentially cramming it into an eight-bit format,” said Gordon Cooper, product manager for Synopsys’ Vision and AI Processor IP. “We’ve done accuracy tests and for almost every neural network-based object detection. We can go from 32-bit floating point to Integer 8 with less than 1% accuracy loss.”
For quality/assurance, there’s often post-quantization retraining to see how converting the floating-point value has affected the network, which could iterate through several passes.
This is why training and inference can be performed using different hardware. “For example, a common pattern we’ve seen is accelerators using NVIDIA GPUs, which then end up running the inference on general purpose CPUs,” said Grisenthwaite.
The other approach is chips purpose-built for inference.
“We’re an inference accelerator. We don’t do training at all,” says Untether AI’s Beachler. “We place the entire neural network on our chip, every layer and every node, feed data at high bandwidth into our chip, resulting in each and every layer of the network computed inside our chip. It’s massively parallelized multiprocessing. Our chip has 511 processors, each of them with single instruction multiple data (SIMD) processing. The processing elements are essentially multiply/accumulate functions, directly attached to memory. We call this the Energy Centric AI computing architecture. This Energy Centric AI Computing architecture results in a very short distance for the coefficients of a matrix vector to travel, and the activations come in through each processing element in a row-based approach. So the activation comes in, we load the coefficients, do the matrix mathematics, do the multiply/accumulate, store the value, move the activation to the next row, and move on. Short distances of data movement equates to low power consumption.”
In broad outline, AI development started with CPUs, often with FP co-processors, then moved to GPUs, and now is splitting into a two-step process of GPUs (although some still use CPUs) for training and CPUs or dedicated chips for inference.
The creators of general-purpose CPU architectures and dedicated inference solutions may disagree on which approach will dominate. But they all agree that the key to a successful handoff between training and inference is a floating-point standard that minimizes the performance overhead and risk of errors during quantization and transferring operations between chips. Several companies, including NVIDIA, Intel, and Untether, have brought out FP8-based chips.
“It’s an interesting paper,” said Cooper. “8-bit floating point, or FP8, is more important on the training side. But the benefits they’re talking about with FP8 on the inference side is that you possibly can skip the quantization. And you get to match the format of what you’ve done between training and inference.”
Nevertheless, as always, there are still many challenges still to consider.
“The cost is one of model conversion — FP32 trained model converted to INT8. And that conversion cost is significant and labor intensive,” said Roddy. “But if FP8 becomes real, and if the popular training tools begin to develop ML models with FP8 as the native format, it could be a huge boon to embedded inference deployments. Eight-bit weights take the same storage space, whether they are INT8 or FP8. The energy cost of moving 8 bits (DDR to NPU, etc.) is the same, regardless of format. And a Float8 multiply-accumulate is not significantly more power consumptive than an INT8 MAC. FP8 would rapidly be adopted across the silicon landscape. But the key is not whether processor licensors would rapidly adopt FP8. It’s whether the mathematicians building training tools can and will make the switch.”
Conclusion
As the quest for lower power continues, there’s debate about whether there might even be a FP4 standard, in which only 4 bits carry a sign, an exponent, and mantissa. People who follow a strict neuromorphic interpretation have even discussed binary neural networks, in which the input functions like an axon spike, just 0 or 1.
“Our sparsity level is going to go up,” said Untether’s Snelgrove. “There are hundreds of papers a day on new neural net techniques. Any one of them could completely revolutionize the field. If you talk to me in a year, all of these words could mean different things.”
At least at the moment, it’s hard to imagine that lower FPs or integer schemes could contain enough information for practical purposes. Right now, various flavors of FP8 are undergoing the slow grind towards standardization. For example,
Graphcore, AMD, and Qualcomm have also brought a detailed FP8 proposal to the IEEE. [4]
“The advent of 8-bit floating point offers tremendous performance and efficiency benefits for AI compute,” said Simon Knowles, CTO and co-founder of Graphcore. “It is also an opportunity for the industry to settle on a single, open standard, rather than ushering in a confusing mix of competing formats.”
Indeed, everyone is optimistic there will be a standard — eventually. “We’re involved in IEEE P3109, as are many, many companies in this industry,” said Arm’s Grisenthwaite. “The committee has looked at all sorts of different formats. There are some really interesting ones out there. Some of them will stand the test of time, and some of them will fall by the wayside. We all want to make sure we’ve got complete compatibility and don’t just say, ‘Well, we’ve got six different competing formats and it’s all a mess, but we’ll call it a standard.”
 ).
).



 Thanks for your wise thoughts Hoppy ❤
Thanks for your wise thoughts Hoppy ❤











