Soundhound (SOUN)....not a stock recommendation but right up Brainchip's alley
Voice assistants
Look at the total addressable market (TAM) and orders backlog for just one company. Clients include Mercedes.
From yahoo
SoundHound AI (
SOUN)
The first AI stock we're looking at is SoundHound AI, a voice assisting specialist. Via speech, its voice AI platform enables consumers to interact with products. This is not some esoteric segment of the market we’re talking about. The company sees a huge TAM (total addressable market) of $160 billion ahead; by 2024, there are expected to be 8 billion voice assistants in use with 75 billion connected devices operating worldwide the following year. SoundHound has some big-name clients on its roster such as Mercedes-Benz, Hyundai, Mercedes-Benz, Kia, Deutsche Telekom, Snap, Stellantis and Vizio.
SoundHound only became a public entity this year, entering the market via the SPAC route back in April. It has been a trial by fire, to say the least. The shares are down by 88% since the debut as SPACs went seriously out of favor in 2022’s bear.
Nevertheless, despite worries about the company being able to withstand the tough macro conditions amidst continued losses, it has been posting some impressive growth. In Q3, revenue climbed by 178% YoY to $11.2 million. The company saw a cumulative bookings backlog of $302 million, amounting to a 239% YoY increase - representing a fourth consecutive quarter of triple-digit growth and a company record.
In November, the company introduced a new product called Dynamic Interaction, a conversational AI tool that enables businesses to use voice AI technology when servicing customers.
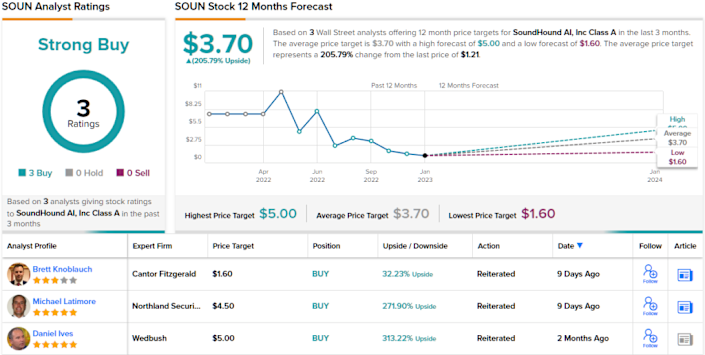
Cantor’s Brett Knoblauch thinks it could be a “game-changing technology as it pertains to how humans interact with computers, and more broadly speaking, technology.”
“We believe there are numerous use-cases that this technology could be utilized for, with low-hanging fruit being within customer-service settings like restaurants,” the analyst went on to add. “We believe this product 1) further expands upon SOUN's conversational AI advantage; 2) gives us greater visibility into SOUN's revenue trajectory; 3) will accelerate the mix-shift of revenue towards subscription revenue; and 4) expands SOUN's addressable market.”
Conveying his confidence, Knoblauch rates SOUN as Overweight (i.e., Buy) and backs it up with a $1.60 price target, implying shares will move ~32% higher over the one-year timeframe. (To watch Knoblauch’s track record,
click here)
Knoblauch, while bullish on the stock, is somewhat conservative compared to the general Wall Street view here. The average price target is higher than Alexanders, at $3.70, implying a strong upside potential of ~206% from the $1.21 share price. Unsurprisingly, SOUN has a Strong Buy analyst consensus rating, based on a unanimous 3 Buys. (See
SOUN stock forecast)
 P
P











 .
.  chip.
chip.