"AI Reinforcement Learning with Weebit ReRAM
05 June, 23
Alessandro Bricalli
A
paper from Weebit and our partners at
CEA-Leti and the
Nano-Electronic Device Lab (NEDL) at Politecnico di Milano was recently published in the prestigious journal Nature Communications. It details how bio-inspired systems can learn using ReRAM (RRAM) technology in a way that is much closer to how our own brains learn to solve problems compared to traditional deep learning techniques.
The teams demonstrated this by implementing a bio-inspired neural network using ReRAM arrays in conjunction with an FPGA system and testing whether the network could learn from its experiences and adapt to its environment. The experiments showed that our in-memory hardware not only does this better than conventional deep learning techniques, but it has the potential to achieve a significant boost in speed and power-saving.
Learning by experience
Humans and other animals continuously interact with each other and the surrounding environment to refine their behavior towards the best possible reward. Through a continuous stream of trial-and-error events, we are constantly evolving, learning, improving the efficiency of routine tasks and increasing our resilience to daily life.
The acquisition of experience-based knowledge is an interdisciplinary subject of biology, computer science and neuroscience known as “reinforcement learning,” and it is at the heart of a major objective of the AI community: to build machines that can learn by experience. The goal is machines that can infer concepts and make autonomous decisions in the context of constantly evolving situations.
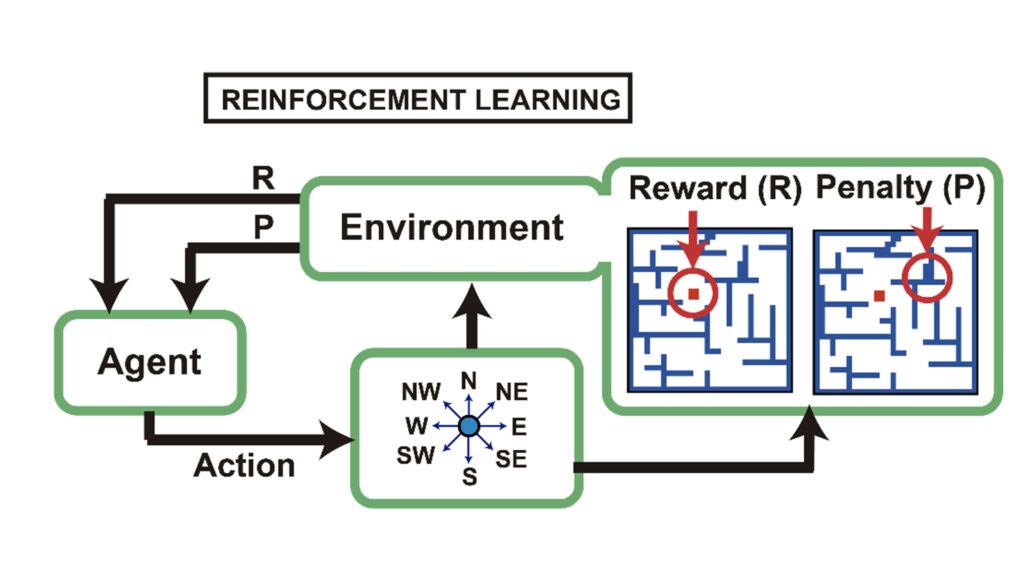
In reinforcement learning, an agent (the neural network) interacts with its environment and receives feedback based on that interaction in the form of penalties or rewards. Through this feedback, it learns from its experiences and constructs a set of rules that will enable it to reach the best possible outcomes.
In developing such resilient bio-inspired systems, what’s needed is hardware with plasticity, i.e., the ability to adjust its state based on specific inputs and rules, as in the case of biological synapses. The lack of such commercial hardware is one of the current main limitations in implementing systems capable of learning from experience in an efficient way.
NVMs for in-memory computing
Researchers are now looking at non-volatile memories (NVMs) like ReRAM to enable hardware plasticity for neuromorphic computing. ReRAM is particularly well-suited for use in hardware capable of plastic adaptation, as its conductance can be easily modulated by controlling few electrical parameters. We’ve talked about this previously in several papers and a
recent demonstration.
When voltage pulses are applied, the conductance of ReRAM can be increased or decreased by set and reset processes. This is how ReRAM stores information. In the brain, synapses provide the connections between neurons, and they can change their strength and connectivity over time in response to patterns of neural activity. Because of this similarity,
ReRAM (
RRAM) arrays can be used to create artificial synapses in a neural network which change their strength and connectivity over time in response to patterns of input. This allows them to learn and adapt to new information, just like biological synapses.
In addition to their ability to mimic the plasticity of biological synapses, memristors like ReRAM have several other advantages for these systems. ReRAM is small, low-power, and can be fabricated using standard semiconductor manufacturing techniques in the backend-of-the-line (BEOL), making it easy to integrate into electronic systems.
Power and bandwidth
Deep learning is extremely computationally intensive, involving large numbers of computations which can be very power-hungry, particularly when training large models on large datasets. A great deal of power is also consumed through the high number of iterative optimizations needed to adjust the weights of the network.
Deep learning models also require a lot of memory to store the weights and activations of the neurons in the network, and since they rely on traditional computing architectures, they are impacted by communication delays between the processing unit and the memory elements. This can be a bottleneck that not only slows down computations but also consumes a lot of power.
In the brain, there are no such bottlenecks. Processing and storage are inextricably intertwined, leading to fast and efficient learning. This is where in-memory computing with ReRAM can make a huge difference for neural networks. With ReRAM, fast computation can be done in-situ, with computing and storage in the same place.
The maze runner
While memristor-based networks are not always as accurate as standard deep learning approaches, they are very well-suited to implementing systems capable of adapting to changing situations. In our joint paper with CEA-Leti and NEDL we propose a bio-inspired recurrent neural network (RNN) using arrays of ReRAM devices as synaptic elements, that achieves plasticity as well as state-of-the-art accuracy.
To test our proposed architecture for reinforcement learning tasks, we studied the autonomous exploration of continually evolving environments including a two-dimensional dynamic maze showing environmental changes over time. The maze was experimentally implemented using a microcontroller and a field programmable-gate-array (FPGA), which ran the main program, enabled learning rules and kept track of the position of the agent. Weebit’s ReRAM devices were used to store information and adjust the strength of connections between neurons, and also to map the internal state of each neuron.
Above: a Scanning Electron Microscope image of the SiOx RRAM devices and
sample photo of the packaged RRAM arrays used in this work
Our experiments followed the same procedure used in the case of the
Morris Water Maze in biology: the agent has a limited time to explore the environment under successive trials, and once a trial starts, the sequence of firing neurons maps the movement of the agent.
Above: Representation of high-level reinforcement learning for autonomous
navigation considering eight main directions of movement
The maze exploration is configured as successive random walks which progressively develop a model of the environment. Here is how it generally progressed:
- At the beginning, the network cannot find the solution and spends the maximum amount of time available in the maze.
- As the network progressively maps the configuration of its environment, it becomes a master of the problem trial after trial, and it finally finds the optimum path towards the objective.
- Once the solution is found, the network decreases the computing time with each successive attempt at solving the same maze configuration, because it remembers the solution.
- Next, the maze changes shape and a different escape path must be found. As it attempts to find the solution, the network receives a penalty in unexpected positions. After an exploration period, it successfully gets to the target again.
- Finally, the system comes back to the original configuration and the network easily retrieves the first solution – faster than before. This is thanks to the residual memory of the internal states and to the intrinsic recurrent structure.
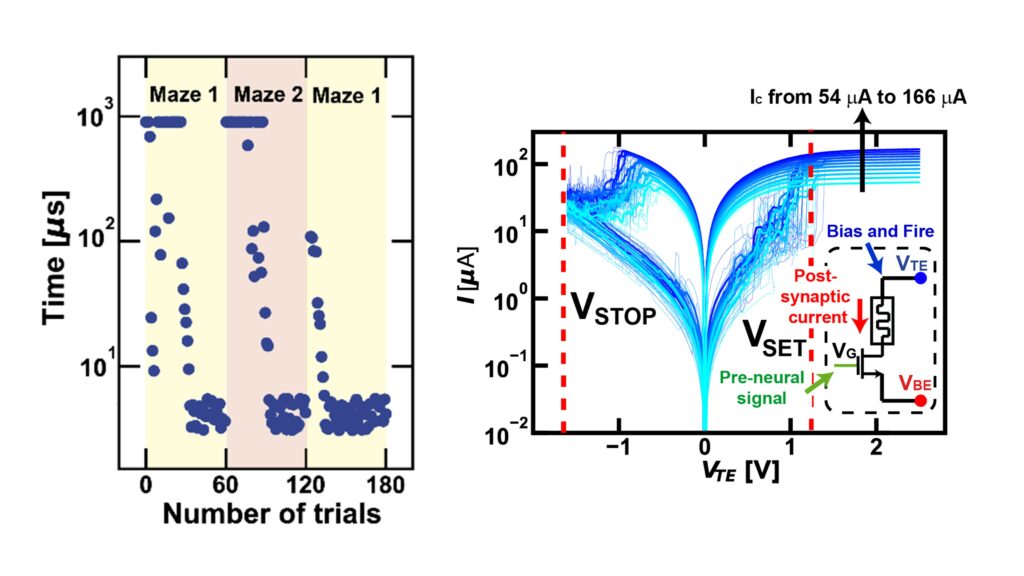
Above: (left) the system re-learns quickly when presented with “maze 1” the second time; (right) ReRAM resistance can be easily modulated by using different programming currents, enabling some memory of the original maze configuration due to gradual adaptation of the internal voltage of the neurons
You can see a short video
here showing the experimental setup and the hardware demonstration of the exploration of the dynamic environment via reinforcement learning.
In our paper, we go into much more detail on the experiments, including testing the hardware for complex cases such as the Mars rover navigation to investigate the scalability and reconfigurability properties of the system.
Saving space with fewer neurons
One of the key features that makes our implementation so effective is that it uses an optimized design based on only eight CMOS neurons, representing the eight possible directions of movement inside the maze. CMOS neurons are generally integrated in the front-end of line (FEOL) and require a large amount of circuitry, so that an increase in the number of neurons is associated to an increase in area/cost.
In our system, the ReRAM, acting as the threshold modulator, is the only thing that changes for each explored position in the maze, while the remaining hardware of the neurons remains the same. For this reason, the size of the network can be increased with very small costs in terms of circuit area by increasing the amount of ReRAM – which is dense and easily integrated in the back-end-of-line (BEOL).
Our bio-inspired approach shows far better management of computing resources compared to standard solutions. In fact, to carry out an exploration at a certain average accuracy (99%), our solution turns out to be 10 times less expensive, as it requires 10 times less synaptic elements (the number of computing elements is directly proportional to the area/power consumption).
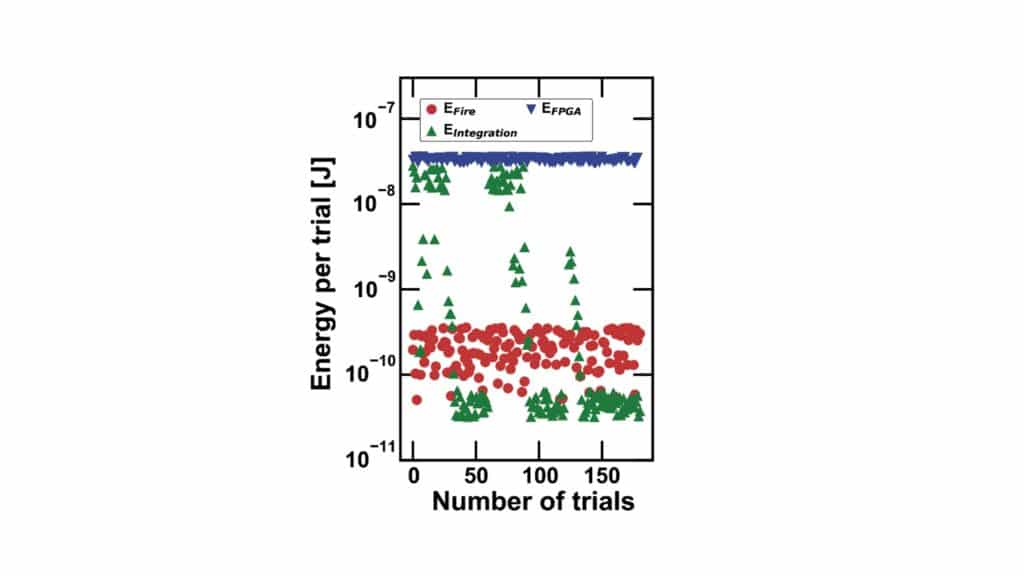
Above: Thanks to the reinforcement learning, the energy consumed by
each neuron drastically decreases as more and more trials are allowed
Key Takeaways
Deep learning techniques using standard Von Neumann processors can enable accurate autonomous navigation but require a great deal of power and a long time to make training algorithms effective. This is because the environmental information is often sparse, noisy and delayed, while training procedures are supervised and require direct association between inputs and targets during the backpropagation. This means that complex models of convolutional neural networks are needed to numerically find the best combination of parameters for the deep reinforcement computation.
Our proposed solution overcomes the standard approaches used for autonomous navigation using ReRAM based synapses and algorithms inspired by the human brain. The framework highlights the benefits of the ReRAM-based in-situ computation including high efficiency, resilience, low power consumption and accuracy.
Since biological organisms draw their capability from the inherent parallelism, stochasticity, and resilience of neuronal and synaptic computation, introducing bio-inspired dynamics into neural networks would improve robustness and reliability of artificial intelligent systems.
Read the entire paper here:
A self-adaptive hardware with resistive switching synapses for experience-based neurocomputing."
https://www.weebit-nano.com/ai-reinforcement-learningwith-weebit-reram/