Hi Frangipani,
Just came across this press release by Tachyum dated August 15 - I had to google EDA tools (which they seem to focus on here) and found out they have to do with software, but then the following sentence obviously refers to changes in hardware, doesn’t it? Please correct me, if I am wrong.
“After the Prodigy design team had to replace IPs, it also had to replace RTL simulation and physical design tools.”
I should, however, add that I also found two articles in German whose authors are both very sceptical about Tachyum’s claims and describe the second generation of the supposed Prodigy wonder chip that - just like the first generation (which was never taped out despite several announcements) - so far only exists on paper, as a castle in the sky and too good to be true. One of the authors remarks that there is one thing Tachyum is even better in than raising money and developing processors, and that is writing press releases on a weekly basis.

50 Prozent mehr Kerne und Cache: Tachyum baut neue Luftschlösser in EDA-Tools
192 Kerne statt geplanter 128, dazu auch 50 Prozent mehr Cache – Tachyum baut in neuen EDA-Tools auch neue Luftschlösser.www.computerbase.de
So while I am not sure what to make of this press release (and have never looked into the company before), I wanted to share it nevertheless, especially since Tachyum liked Brainchip on LinkedIn a couple of months ago.
If their processor upgrade is indeed about switching to Akida IP (I suppose that would have to be through Renesas or MegaChips then, since there has been no new signing of an IP license?), that would explain both the postponement of their universal processor’s tape-out as well as their claims of “industry leading performance” and “potential breakthrough for satisfying the world’s appetite for computing at a lower environmental cost” that a lot of tech experts have been questioning. Tachyum states that “Delivery of the first Prodigy high-performance processors remains on track by the end of the year.” We will see. In various ways.
View attachment 42431

Tachyum Achieves 192-Core Chip After Switch to New EDA Tools | Tachyum
Tachyum achieved significantly better results with chip specifications than previously anticipated – including an increase in the number of Prodigy cores to 192www.tachyum.com
- Aug 15, 2023 4 minutes to read
Tachyum Achieves 192-Core Chip After Switch to New EDA Tools
LAS VEGAS, August 15, 2023 – Tachyum® today announced that new EDA tools, utilized during the physical design phase of the Prodigy®Universal Processor, have allowed the company to achieve significantly better results with chip specifications than previously anticipated, after the successful change in physical design tools – including an increase in the number of Prodigy cores to 192.

After RTL design coding, Tachyum began work on completing the physical design (the actual placement of transistors and wires) for Prodigy. After the Prodigy design team had to replace IPs, it also had to replace RTL simulation and physical design tools. Armed with a new set of EDA tools, Tachyum was able to optimize settings and options that increased the number of cores by 50 percent, and SERDES from 64 to 96 on each chip. Die size grew minimally, from 500mm2 to 600mm2 to accommodate improved physical capabilities. While Tachyum could add more of its very efficient cores and still fit into the 858mm2 reticle limit, these cores would be memory bandwidth limited, even with 16 DDR5 controllers running in excess of 7200MT/s. Tachyum cores have much higher performance than any other processor cores.
Other improvements realized during the physical design stage are:
“At every step of the process in bringing Prodigy to market, our innovation allows us to push beyond the limits of traditional design and continue to exceed even our lofty design goals,” said Dr. Radoslav Danilak, founder and CEO of Tachyum. “We have achieved better results and timing with our new EDA PD tools. They are so effective that we wish we had used them from the beginning of the process but as the saying goes, ‘Better now than never.’ While we did not have any choice but to change EDA tools, our physical design (PD) team worked hard to redo physical design and optimizations with the new set of PD tools, as we approach volume-level production.”
- Increase of the chip L2/L3 cache from 128MB to 192MB
- Support of DDR5 7200 memory in addition to DDR5 6400
- More speed with 1 DIMM per channel
- Larger package accommodates additional 32 serial links and as many as 32 DIMMs connected to a single Prodigy chip
As a universal processor, the patented Prodigy architecture enables it to switch seamlessly and dynamically from normal CPU tasks to AI/ML workloads, so it delivers high AI/ML performance in both training and inference. AI/ML is increasingly important in the banking industry, and used to identify fraud and cyberattacks before serious financial damage can be done.
Prodigy delivers unprecedented data center performance, power, and economics, reducing CAPEX and OPEX significantly. Because of its utility for both high-performance and line-of-business applications, Prodigy-powered data center servers can seamlessly and dynamically switch between workloads, eliminating the need for expensive dedicated AI hardware and dramatically increasing server utilization. Tachyum’s Prodigy delivers performance up to 4x that of the highest performing x86 processors (for cloud workloads) and up to 3x that of the highest performing GPU for HPC and 6x for AI applications.
With the achievement of this latest Prodigy milestone, Tachyum’s next steps are to complete the substrate package and socket design to accommodate more SERDES lines. Delivery of the first Prodigy high-performance processors remains on track by the end of the year.
Follow Tachyum
https://twitter.com/tachyum
https://www.linkedin.com/company/tachyum
https://www.facebook.com/Tachyum/
About Tachyum
Tachyum is transforming the economics of AI, HPC, public and private cloud workloads with Prodigy, the world’s first Universal Processor. Prodigy unifies the functionality of a CPU, a GPGPU, and a TPU in a single processor that delivers industry-leading performance, cost, and power efficiency for both specialty and general-purpose computing. When hyperscale data centers are provisioned with Prodigy, all AI, HPC, and general-purpose applications can run on the same infrastructure, saving companies billions of dollars in hardware, footprint, and operational expenses. As global data center emissions contribute to a changing climate, and consume more than four percent of the world’s electricity—projected to be 10 percent by 2030—the ultra-low power Prodigy Universal Processor is a potential breakthrough for satisfying the world’s appetite for computing at a lower environmental cost. Prodigy, now in its final stages of testing and integration before volume manufacturing, is being adopted in prototype form by a rapidly growing customer base, and robust purchase orders signal a likely IPO in late 2024. Tachyum has offices in the United States and Slovakia. For more information, visit https://www.tachyum.com/.

Here's a peek at a couple of Tachyum patents:
US10915324B2 System and method for creating and executing an instruction word for simultaneous execution of instruction operations 20180816 DANILAK RADOSLAV
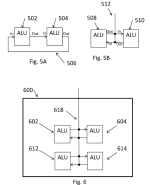
a processing architecture and related methodology that utilizes location-aware processing that assigns Arithmetic Logic Units (ALU) in a processor to instruction operations based on prior allocations of ALUs to prior instruction operations. Such embodiments minimize the influence of internal transmission delay on wires between ALUs in a processor, with a corresponding significant increase in clock speed, reduction in power consumption and reduction in size.
A methodology for creating and executing instruction words for simultaneous execution of instruction operations is provided. The methodology includes creating a dependency graph of nodes with instruction operations, the graph including at least a first node having a first instruction operation and a second node having a second instruction operation being directly dependent upon the outcome of the first instruction operation; first assigning the first instruction operation to a first instruction word; second assigning a second instruction operation: to the first instruction word upon satisfaction of a first at least one predetermined criteria; and to a second instruction word, that is scheduled to be executed during a later clock cycle than the first instruction word, upon satisfaction of a second at least one predetermined criteria; and executing, in parallel by the plurality of ALUs and during a common clock cycle, any instruction operations within the first instruction word.
As you can see, Tachyum are big on ALUs.
It also seems to be unasynchronous.
This one is more recent:
EP3979070A1 SYSTEM AND METHOD OF POPULATING AN INSTRUCTION WORD 20190815
A methodology for populating an instruction word for simultaneous execution of instruction operations by a plurality of arithmetic logic units, ALUs), in a data path includes creating a dependency graph of instruction nodes, and initially designating any in the dependency graph as global, whereby the corresponding instruction node is expected to require inputs from outside of a predefined limited physical range of ALUs smaller than the full extent of the data path. A first available instruction node is selected from the dependency graph and assigned to the instruction word. Also selected are any available instruction nodes that are dependent upon a result of the first available instruction node and do not violate any predetermined rule, including that the instruction word may not include an available dependent instruction node designated as global. Available dependent instruction nodes are assigned to the instruction word, and the dependency graph updated to remove any assigned nodes from further assignment consideration.
In their blurb, they claim to have designed an all-in-one CPU-GPU-TPU, which they claim performs better than CPUs and GPUs. They need the ALUs to do the CPU/GPU work, but ALUs work on multi-bit numbers, not spikes.
Tachyum’s Prodigy delivers performance up to 4x that of the highest performing x86 processors (for cloud workloads) and up to 3x that of the highest performing GPU for HPC and 6x for AI applications.
Taking Tachyum at their word, this is very commendable, but doing Al/ML on even the best organized CPU/GPU/ALU arrangement will always be inferior to Akida.
(I think that, to accommodate 8-bit weights and actuations, Akida does include a couple of ALUs in the input layer NPUs, but the internal layers only process up to 4-bit weights & actuations)